With the market of the chatbots completely booming, it has never been more important to give them a voice and moreover, a human-like one. New technologies in Artificial Intelligence make that possible. In this post we will show you how exactly you can use Google technologies to make a bot speak a certain language: Flemish. As this is a very local language, spoken only by about 7 million people, no big tech company adapts these state-of-the-art methods to it (yet!).
However, we do feel that it can be an appreciated feature for all those native Flemish speakers to have their bot or voice assistant speak their very own language variant, not the generic Dutch version of it. So during our internship at Fourcast we decided to go and try to make what the giants didn’t: a Flemish-speaking bot voice!
This blog post will follow our journey into voice synthesis as we lived it in the past month. We will talk about the different technologies, how we used them on English language first, how we built a Flemish dataset and finally the results (and the problems!) we obtained.
Choosing a model
The first step of our journey consists in finding an open-source text-to-speech model to build onto. There are several text-to-speech technologies out there, but most of them require very complex sets of data in order to produce results. In other words, they need to know the correspondence between words, sounds and phonetic alphabet for each text of the training test.
However, Google has recently developed a new machine learning model: the Tacotron (because they love tacos)!
The Tacotron only requires matching sound/text samples in order to learn to speak. Then, from a given text, the model predicts a mel-spectrogram (see picture below) which is an acoustic time-frequency representation of a sound.
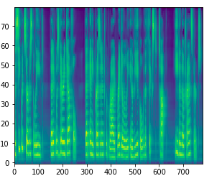
From that representation it is possible to generate audio using either an iterative algorithm (Griffin-Lim) or another neural network model called Wavenet. The latter produces very good results that can in the best case be compared to human voice. But it also has to be trained using audio samples.
“Generative adversarial network or variational auto-encoder” Example:
Model Testing in English
To be sure that the models would work for our purpose and would produce the expected results, we first tested them with an English dataset. This dataset was specifically designed for the purpose of voice synthesis and is named LJSpeech. As we had to make the models run and also bridge some of them together, we tried to automate those parts by using as much scripting as possible.
The results on the English version were promising with only a few hours of training of the models, whereas normally a few days are expected to get the best results. Moreover, the inference time – the time needed to produced the voice from the text – was very fast: ~1.2 seconds max for an average sentence. We were then confident that the technology would work for Flemish too, at least with the right dataset, and moved on to the next step.
Monitoring during training
A fundamental question in constructing a voice for a bot is: “how to know if your model is getting better during the training phase?”. Measuring the quality of your model at fixed points in time during the training of it is very important. Taking many measures is useful to see the average behaviour of your model and to avoid incorrect conclusions. Indeed, one could listen to a difficult sample for the model that was synthesized badly and conclude that the model is no good, where it might actually have improved.
Good measurements and interesting visualisation not only gives us an idea on how well our synthesis will perform, but it can also show us the pros and cons of the dataset we use. It shows us if the dataset has too many mistakes, is too hard to understand for the model or if there are not enough samples. To do so, we use the Tensorboard visualisation tool which allows remote access to all that information. As a training may take days and is often done in the cloud, it is essential to have a remote way of controlling what is happening.
To know if our audio will be good or is at least progressing before even listening to it, we mainly used two different measures:
The training/validation loss, which is a measure of the difference between the result predicted by our model and the actual result. Here is an illustration.
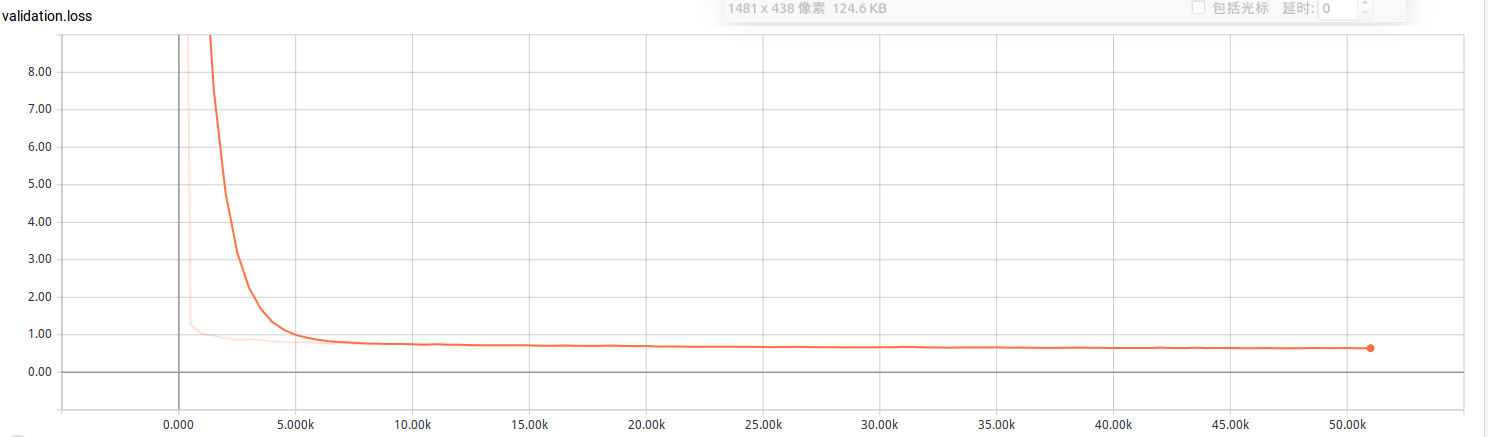
We can see on that graph that there is a quick improvement in the training, but afterwards it doesn’t improve anymore. We say that the model has converged, and we can safely stop the training.
The alignment graph, which shows if attention mechanism has been learned. It’s helpful as a visualization: if the diagram shows a thin straight diagonal line, we know the audio will be good. If the line is thick, erratic or there is simply no line, the audio will not be understandable.
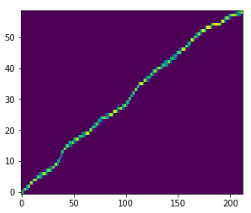
This diagram shows a pretty good alignment.
Ingesting the data
Before even starting to look for the potential Flemish dataset, we had to discover what kind of audio samples we needed. According to the previous work by others with Tacotron, we knew that we would need at least 10h hours of small audio samples (1~15 secs) with their transcription. The audio needed to be of high quality, without noise, with a single speaker and a neutral tone.
The first idea we had was to find an already existing dataset in Flemish, to cut costs and save ourselves time. We found the “Gesproken Corpus Nederlands” containing 1000 hours of audio, of which 300 hours are in Flemish. However, the quality of the audio samples is very bad and wouldn’t be suitable for our model learning.
Therefore, we turned to audiobooks. They have the advantage to be of good audio quality, single-speaker and generally with a neutral tone.
The big part of the work is then to cut an audiobook of 10 hours into samples of 1-15 seconds along with their transcription. We automated some parts of this process:
- Cutting the text into short samples (generally one sentence)
- Create a text file linking those text samples to audio file names
- Cutting an audio based on timestamps
This left us with one part to do manually: finding the timestamps corresponding to the beginning and end of each text sample in the audio file.
We started doing this fully manually: we listened to the audio, pressed pause at each beginning/end of sample, and write the timestamp (100ms precision) in a file.
This…. was…. soooo…. sloooow.
Automation for the win
We realised we would not have the time to complete this task in the short amount of time we had. Thus, we modified an existing audio player in such a way that whenever we press the return key while listening, it writes directly in the timestamps file. Without having to pause and write the timestamps ourselves, we finished the task much faster.
The produced audio samples were good, but sometimes lacked precision: the audio was cut a bit too early or too late, the speaker made a mistake so there was a mismatch between audio and transcription, etc.
The whole Fourcast team helped us finding these small mistakes by listening to the samples and pointing the ones that contain a mistake. We could then correct those by manually modifying the timestamps and regenerating the audio.
Finally, we could move on to the training part.
The end of the road: let’s train!
We trained our models on the Google Cloud Platform twice: once before correcting the dataset and once after. With the corrected dataset, we obtained understandable Flemish after only 10 hours of training of our models!
Unfortunately, the quality of the sound is pretty bad, and doesn’t improve with a longer training nor with a wavenet synthesizer. Here you can listen to the results with and without wavenet:
“Ik woon in een groot huis en ik zou graag frietjes eten.” was our example sentence you can hear for both with and without Wavenet:
Griffin-Lim
Wavenet
Here we can see and hear that the Wavenet version produces a better quality voice, but also has a lot of noise in the background. This is due to the low quality spectrogram we gave it, and this in return is due to several reasons which we will explain below.
How to improve?
We did not have the time to improve those results, but our experience built while working on this project and comparisons with other works allow us to come up with some ideas for improvement.
In our opinion, the main reason why our results couldn’t get better is the quality of the audio. In fact, the audiobooks we used were in MP3 format. This is a compressed audio format and for this reason, the spectrograms used to train our model were not of a very good quality.
Also, we used a training set of ~10 hours of audio, which is considered the bare minimum to train a model. Several more hours could really help the training.
Finally, the audiobooks are a good choice, but far from the best. Undoubtedly, a dataset based on professional speaker registerings as in the LJ Speech Dataset (mentioned earlier) produces much better results.
Conclusion
We finally obtained a result of which we are pretty proud: our text-to-speech can say any Flemish sentence properly! Although the result quality is not sufficient to be used in a real-world application, this is already a good start. We also came up with some ideas to improve these results, based on our experience with the Tacotron model.
If we were to give a single advice, it would be this one: take the time to build a proper dataset, even if it requires 60% of the time spent in the project. Because, as is often the case in machine learning, it is the data and not the learning model that allows you to create powerful models. Before starting this project, we were wondering: “why didn’t Google, with their powerful tacotron, release voice synthesis in every language?”. Now we know the answer. They need excellent quality datasets to achieve those remarkable results and it takes a lot of time and money to create this. That’s why minor languages and dialects are not well represented yet in the Google Speech API’s.
Our internship already comes to an end, but we hope our work will gives Fourcast a small head start in building the first Flemish text-to-speech engine!
This post was written by our two amazing interns Florian Vanhee and Thibault Hermans. Thank you guys, for your motivation and persistence!
Also interested in doing an internship at Fourcast? Send your CV to recruitment@fourcast.io or contact us at +32 484 77 80 32!

