
Are you developing data pipelines on Google Cloud and you sometimes struggle to choose the right product ? Do you feel like a combination of various products could be suitable to your solutions and don’t know which one to use in which scenario? If your answer to these questions is yes, carry on reading. In this post, I’ll explain how you can decouple Google Cloud Dataflow with Cloud Tasks and Cloud Functions.

Be daring, be different, be impractical, be anything that will assert integrity of purpose and imaginative vision against the play-it-safers, the creatures of the commonplace, the slaves of the ordinary. — Cecil Beaton
We (a team of developers at Fourcast) recently had to develop a pipeline for a customer that had to fetch data from BigQuery, apply transformations, save the transformed data on a bucket on Google Cloud Storage and then send the results as json to an endpoint.
That all sounds like a perfect use case for Google Cloud Dataflow and that’s how we started.
Leveraging Google Cloud Dataflow
As the amount of data was quite important, we wanted to leverage Dataflow, the highly scalable product of Google Cloud that is simple to start with thanks to the Apache Beam library.
Our simplified architecture looked like this:
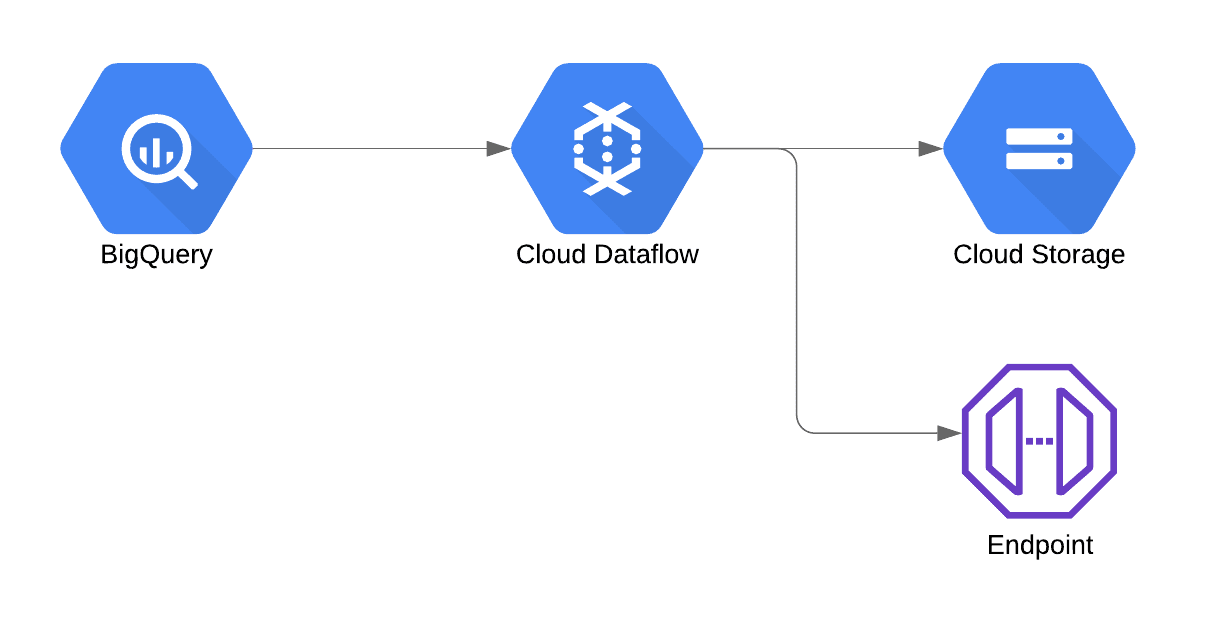
However, we soon faced quite an issue as the endpoint could not always handle the load Dataflow was sending, causing Dataflow to continue scaling and retrying to post the data to the endpoint. Cost started to skyrocket during these episodes and we needed to come up with a solution.
Having no control over the endpoint that was receiving the data, we had to find a solution on the ingestion side.
Finding solutions on the ingestion
We then thought about two solutions:
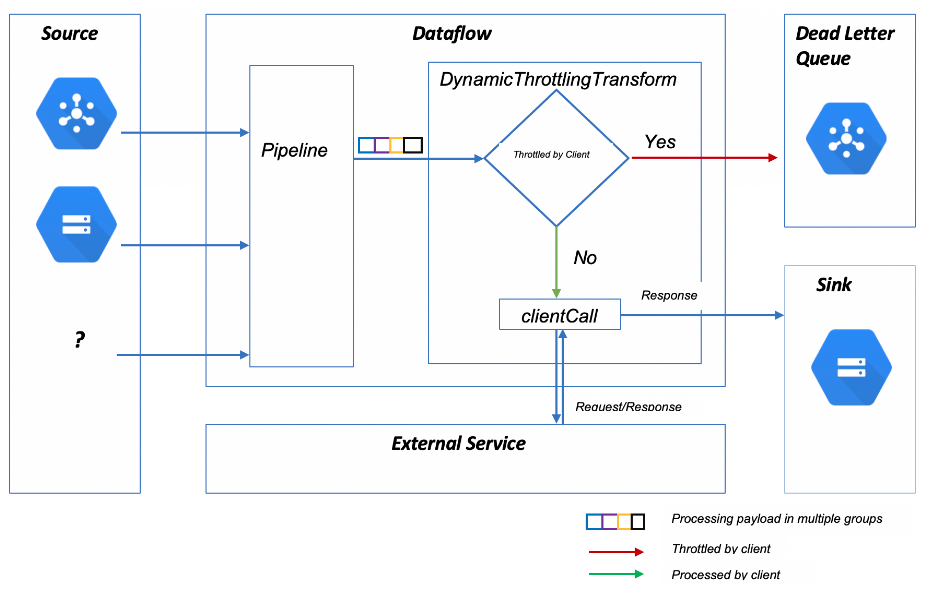
- Implementing client-side throttling in our Apache Beam Python code: while this works pretty well with Java, stateful processing is not yet working properly in Python with the Dataflow runner. If you are using Apache Beam with Java, you can use the code in the previous link and it will work just fine. You will then be able to do dynamic throttling as per following architecture (image taken from the github repository).
- Implementing exponential backoff for our post requests to the endpoint. Apache Beam has a built-in function for this. While this could have been easily implemented, the problem lied in the external service that was blocking the request for a long period of time once we reached its quota limits. Therefore all the messages that got a quota limit error (in our case 500 or 503) are kept in the pipeline and the ParDo functions are waiting to handle the request. This caused Dataflow to spawn a lot of instances while sitting idle. And this of course led to a significant waste of budget.
Decoupling post requests from Dataflow
After trying hard to make the previous two solutions work efficiently, we came up with the idea of decoupling the post requests from Dataflow and handing over this operation to Cloud Tasks and Cloud Functions.
Cloud Tasks has retry with exponential backoff implemented by default, and we were already saving the transformed data on GCS.
So only a few changes were needed:
- Remove the POST request operation from Dataflow.
- Replace the POST request operation with a step that creates a task on Cloud Task with a payload having the Cloud Storage url of the data to be posted to the endpoint.
- Create a Cloud Function to handle the tasks. This handler will get the data from Cloud Storage and will post it to the endpoint (i.e. last step Dataflow in previous implementation).
Benefits of a decoupled Dataflow architecture
We now had the following decoupled architecture with various benefits.
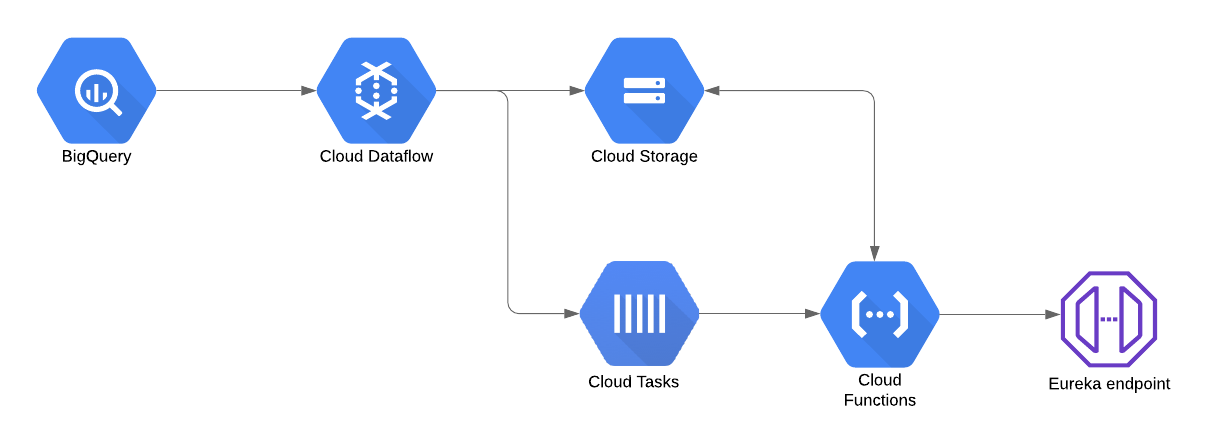
The first benefit is that Dataflow is now fully focused on transforming the data and dumping it on Cloud Storage. We use it for what it’s best at and between two Google Cloud modules (BigQuery and Cloud Storage). This will optimise the cost of Dataflow as it will now scale up, do its job and then terminates seamlessly.
The second benefit is the fact we transferred the problematic operation to Cloud Tasks and Cloud Functions. Both services are cheap and serverless and more importantly we can leverage the retry with exponential backoff that is built in within Cloud Tasks.
While working with Google Cloud (and this is true for any Cloud provider), you might encounter a multitude of products that can solve your problem. It’s a whole art of deep diving into the features of each product to choose the one that fits at best your use case. And sometimes it’s worthwhile to use multiple products and use the best out of each one of them to decouple your problem and have a robust solution, like for the decoupling Dataflow example in this post.
The Cloud evolves at a very fast pace and even professionals might have a hard time keeping up with this speed. At Fourcast we have dedicated teams specialising in specific areas on Google Cloud and this enables us to stay on top of the game in each area.
If you need any recommendations on how to build at best your data pipelines, contact us!

