In this article about deploying multi-tenant Kubernetes deployments in a VPC-native cluster with Spinnaker on Google Kubernetes Engine (GKE), you will learn: how you can use Terraform to create dedicated network resources for your cluster, set up a multi-tenant VPC-native Kubernetes cluster in GKE & Install and configure Spinnaker. You’ll also learn how to use Google Cloud Build to build your application artefacts and how to use both Cloud Build and Spinnaker to automatically deploy a new version of your application based on code changes in your GitHub repository.

This article is part 1 of a series on how to set up secure multi-cluster CI/CD pipelines with Spinnaker on Google Cloud, using Terraform:
- Part 1: Deploying multi-tenant Kubernetes Deployments in a VPC-native cluster with Spinnaker on Google Kubernetes Engine (GKE) (this article)
- Part 2: Using Spinnaker for multi-cluster deployments in clusters
- Part 3: Improving security of your GKE cluster: Private clusters (coming soon)
- Part 4 Protect your Spinnaker applications and accounts with RBAC (coming soon)
Building SaaS applications with proper CI/CD
When building a SaaS product, it is important to publish a stable version and be able to quickly push new versions to your customers. Without the proper solution in place, it can take months before customers can use the newest version of your product.
When building a product, you want to have:
- Short release cycles
- Quick feedback during development to detect bugs as quickly as possible
- Better collaboration within the team
as these three things lead to innovation and higher product quality.
Part of adopting a DevOps culture means relying on a CI/CD solution to eliminate toil and achieve these objectives.
Overview of the CI/CD solution
In this article, we are going to use Terraform to build a CI/CD solution using a VPC-native cluster powered by the Google Kubernetes Engine (GKE). With Google Cloud Build, we will trigger branch-specific builds on code changes from a GitHub repository. Spinnaker will automatically deploy the relevant Kubernetes resources in the cluster once the artefacts are available in Container Registry.
The architecture in the figure below shows an overview of the system we are going to build in this article:
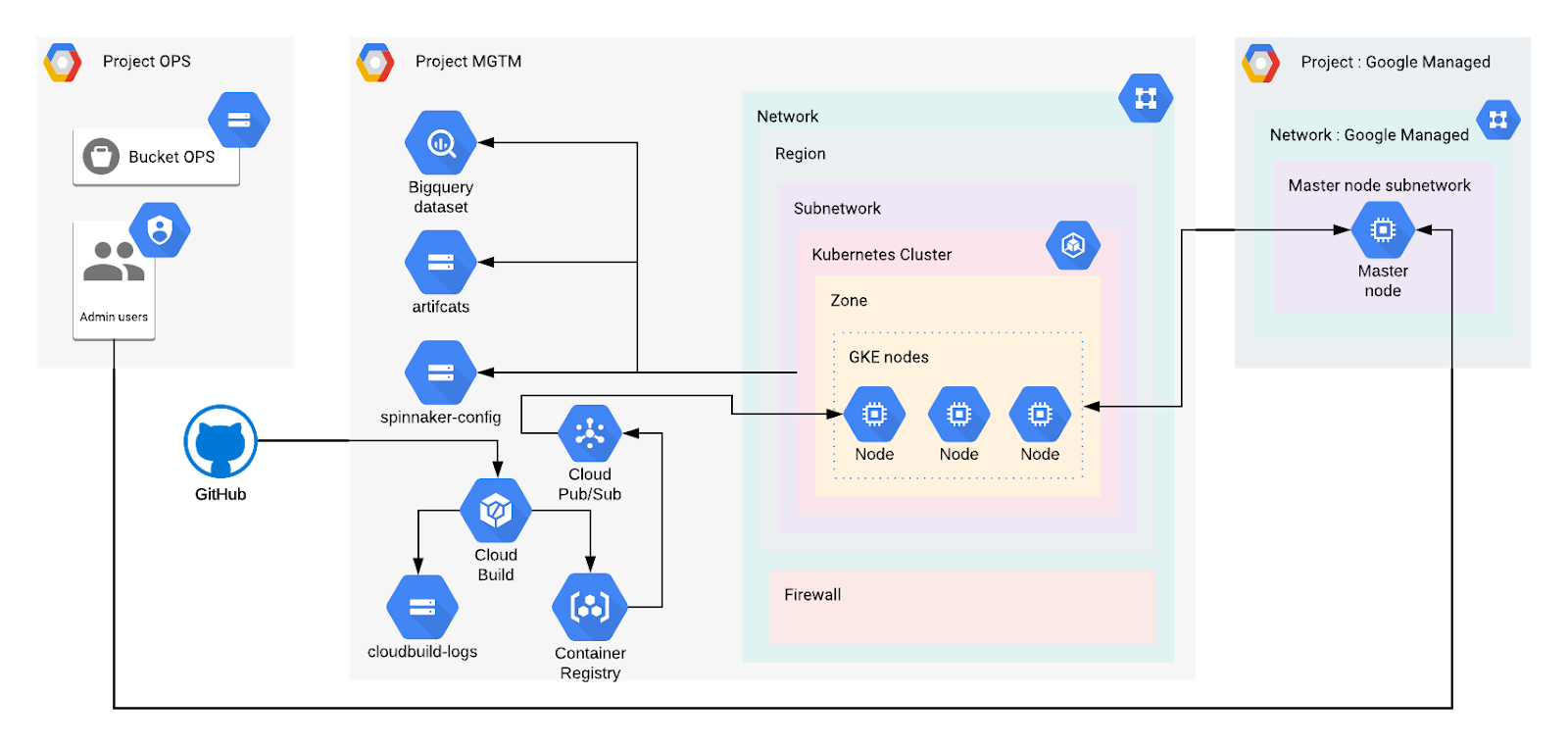
We have three projects:
- Project OPS: A initial project used to store administrative resources (Users, Service accounts, bucket for Terraform states)
- Project MGMT: The project containing the Kubernetes cluster and our CI/CD resources
- Google Managed: A project automatically created and managed by Google, hosting the Master node.
We want to deploy a VPC-native cluster, so we also define a custom subnetwork with specific IP ranges. In addition, we need to set up a set of firewall rules. The cluster is created in the Google Kubernetes Engine. In this article, we use a single-zone cluster. Multi-zonal clusters or Regional clusters are recommended to prevent any downtime during an upgrade of the cluster or an outage of the zone.
Terraform modules

When using Terraform, it is important to split the resources in multiple modules. This helps in structuring, maintenance and reusability of resources that belong together. Here, we split the resources in 3 different Terraform modules:
- gcp_project
- gke
- cicd
A fourth module, called the root module, is implicitly defined. Terraform always requires a root module. The root module should contain providers definitions and references to other modules (called submodules) only. It is usually not recommended to define the providers within a submodule.
gcp_project module
The gcp_project module regroups resources related to the project only. Typically this is where we want to create the project itself, enabling some google APIs and creating VPC networks. We also define firewall rules and gateways.
gke module
The gke module groups resources related to the Kubernetes Engine cluster. This includes the Google Kubernetes Engine cluster itself, service accounts for the nodes for example. As we are creating a VPC-native cluster, we also define a dedicated subnetwork with specific IP ranges for the nodes, pods and services.
cicd module
The cicd module contains all CI/CD resources including service accounts, buckets, PubSub topics, Spinnaker installation and Kubernetes resources.
In this case, we are not using Google Cloud Repository but GitHub to store our code. Therefore, the triggers cannot be created by Terraform if the project is not registered with a GitHub repository. Registering a GitHub repository in the project cannot be done before the project is created. For this reason, we don’t create any triggers the first time we create the infrastructure.
root module
As stated before, the root module is implicit. It is where we store the main Terraform file. The main Terraform file typically contains the backend configuration, providers configurations, and submodules definitions.
Creating the infrastructure
Terraform creates resources in parallel. However, resources often depend on other resources. To do so, Terraform relies on resource dependencies to create them in the right order. This mechanism is not built-in for modules as of version 0.12.
However, with some key concepts, it is possible to create resources from different modules in the expecting order.
To learn more about how to create resource and module dependencies, read our other article on the subject.
Applying terraform code
Once the Terraform modules are written and all dependencies are defined, we can use the root module to apply all our infrastructure changes. Terraform provisions the variables defined in the variables.tf files with the values defined in a specific file. We use the file mgmt.tfvars to set up the values.

Alternatively, it is possible to create the plan and apply it in a single command:

This will produce a plan in the current shell session and requires manual confirmation before applying it. This is fine for small plans, but large plans won’t fit in the terminal. Thus it is recommended to save the plan with the plan command for review first, before specifically applying this plan. This is also a good practice in an automated environment.
Terraform then starts to create the infrastructure according to the plan. Note that depending on the resources, it might take a while before your infrastructure is ready.

We can see that Terraform is creating resources in a specific order based on the relationship we defined, and not based on the order the modules are called.
The cicd module creates a Kubernetes Ingress to expose Spinnaker to the internet. To be able to access it we need to register the static IP used by the Kubernetes Ingress as an A DNS record in our DNS service. This is out of the scope of this article.
Registering the project with GitHub
To be able to create Cloud Build triggers for a GitHub repository, we need to link the project to the GitHub repository.
- From the MGMT project, navigate to Cloud Build > Triggers and click Connect repository
- Select the GitHub (Cloud Build GitHub App) source and click Continue
- Select the GitHub repository and confirm. You will have to authenticate to GitHub to validate the installation.
Once the repository is linked, it is possible to create Cloud Build triggers listening to changes in the GitHub registry.
Adding an application
Now that we have set up our environment, we are able to add application code and use the CI/CD pipelines to automatically deploy our application in the Kubernetes cluster. To do so, we create a very basic web application in Go which returns a “Hello World” message. Kubernetes being a container orchestrator, we dockerise our application with a Dockerfile. Finally, we expose our application with a Kubernetes Ingress.
The structure of our application is split between the application code (cmd), the cicd files and some Terraform code.
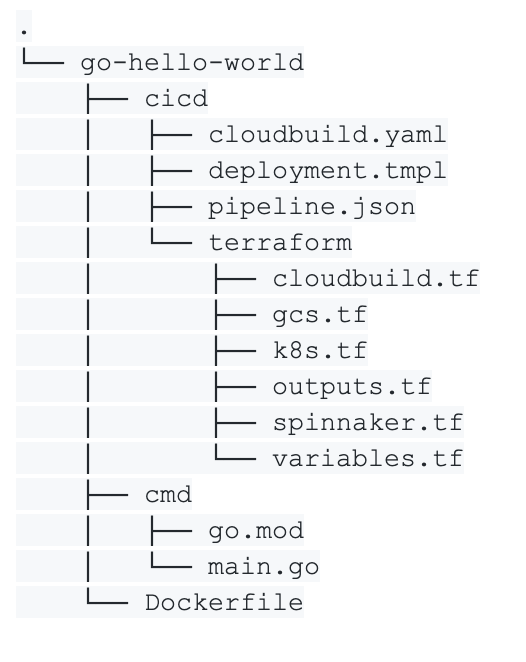
In the cicd folder, we write a Cloud Build file which is used by Cloud Build to build our Docker image and push it into the Docker registry. We also define a deployment.yaml file as a template which is used to generate a raw deployment file required by Kubernetes.
The pipeline.json file is a template describing the Spinnaker pipeline for this application. Finally, we write some Terraform code to create resources the application requires.
For example, we know we need to define a Cloud Build trigger, some Kubernetes resources (in this case a Deployment, Service and an Ingress), the raw deployment file and the Spinnaker pipelines. The Deployment and Service are not defined in Terraform but in the deployment.yaml file, which can be managed by Spinnaker directly.
Now that we defined everything we need, we can reference this application as a module in our root module in the mgmt.tf file

and run Terraform to update our infrastructure. This generates a new plan to update the current infrastructure to a new target state. The variables of this module are used to configure our application.
At this point, Terraform added two important parts of our CI/CD solution for our application
- The Cloud Build trigger
- The Spinnaker pipeline
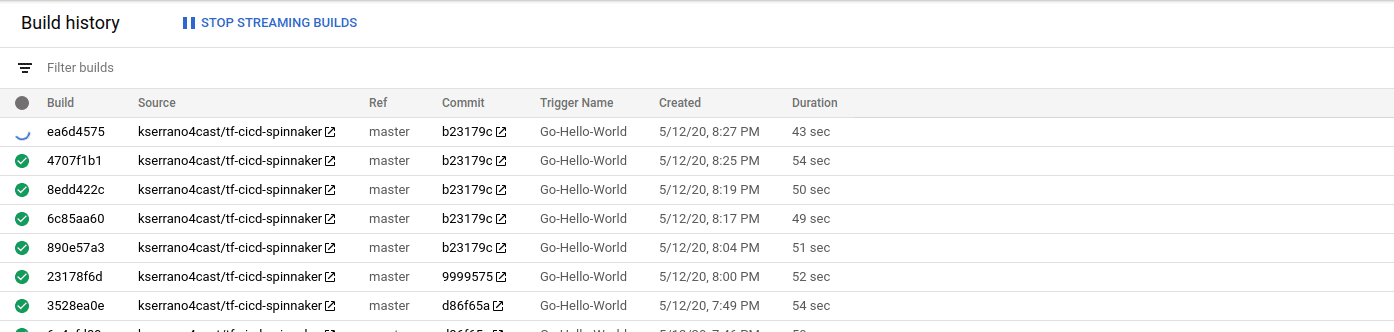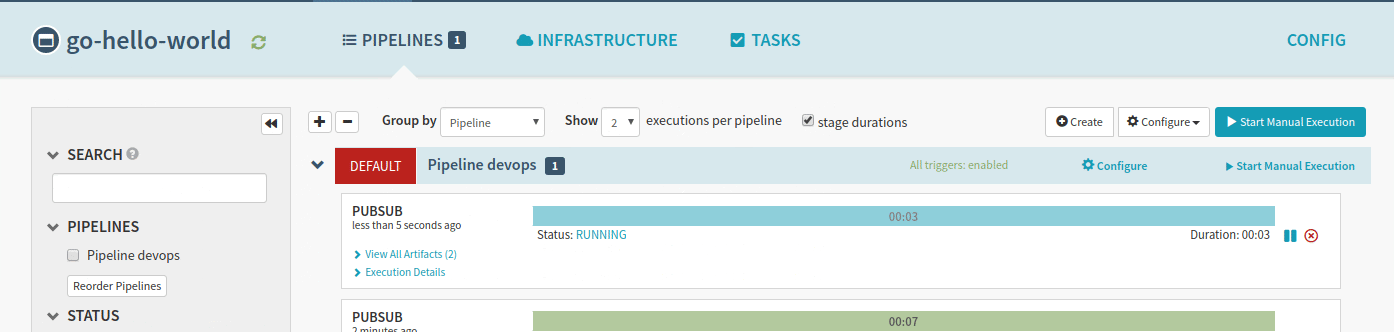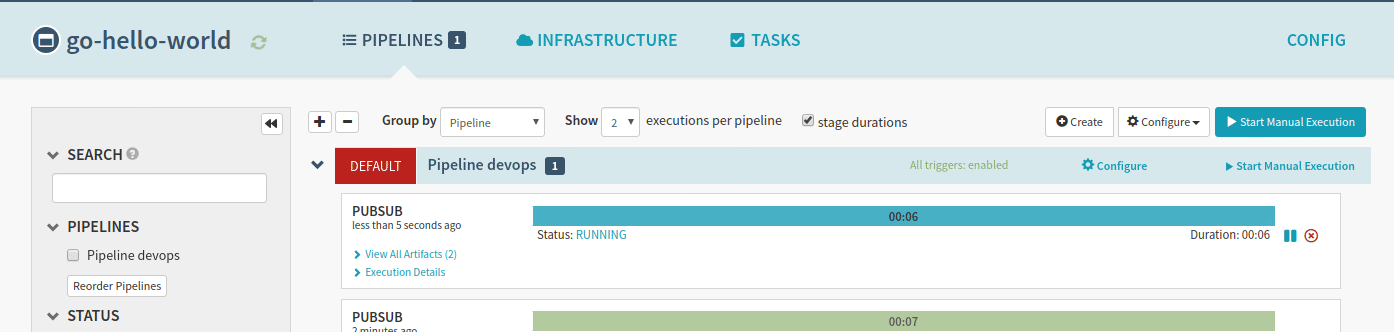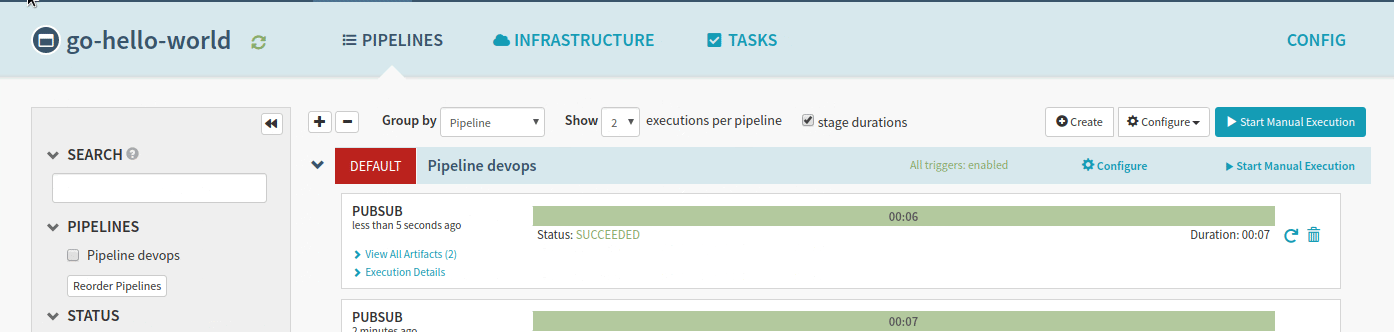
Because of our trigger definition, a code change in the master branch will trigger a new build. In our cicd module, we defined PubSub resources which Spinnaker can use to trigger pipelines. When a new build is pushed by CloudBuild in the container registry, PubSub automatically triggers the associated spinnaker pipelines.
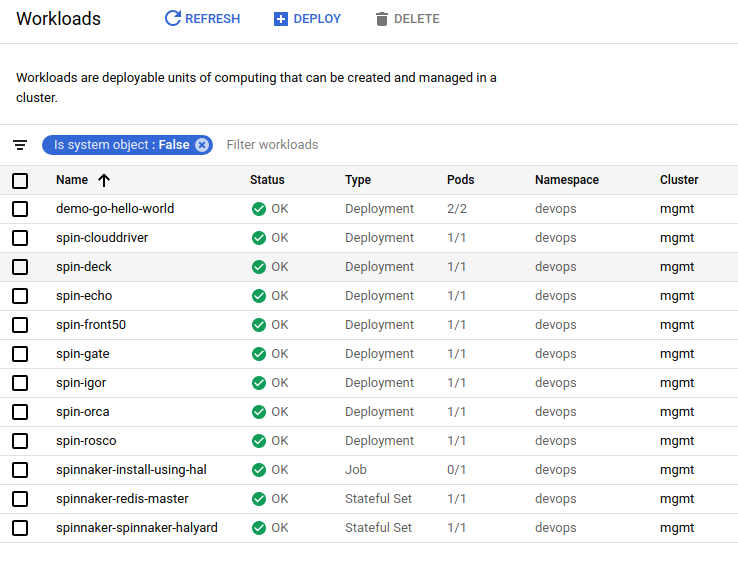
The application is now available in the Kubernetes cluster!
Accessing the application
Terraform has created an Ingress for our application and Spinnaker deployed it in the cluster. We can now access it by visiting the public IP of the Ingress we created in our hello_world module.
You should see the “Hello World” message.
Conclusion
By setting up a CI/CD solution for your environment, it is possible to greatly improve the quality of your product and to quickly and reliably push new versions to your customers. A change in the codebase is automatically tested, built and deployed with CI/CD tools like CloudBuild and Spinnaker. This provides really quick implementation feedback. Using Terraform, you can write your infrastructure as code and manage it with a version control tool like git, while managing resources per business logic regrouped into Terraform modules.
What’s next?
In part 2 of this series about ‘Setting up secure multi-cluster CI/CD pipelines with Spinnaker on Google Cloud Platform using Terraform’, we will improve the current infrastructure to use multiple environments such as Development, Staging and Production. You’ll also see how to use Spinnaker to deploy our applications in different environments based on git branches, and to restrict access to the Kubernetes resources based on namespaces.
Questions? Need guidance from experts? Contact Us today!

