From your Google web search results to your Facebook newsfeed, recommender systems are omnipresent. In a nutshell, a recommender system will make sure that you see relevant pieces of content while you scroll on Facebook or that you see the correct search results on Google. They are one of the oldest and most widely available artificial intelligence algorithms, though in practice users often complain about their accuracy. Indeed, state-of-the-art recommender systems often require specialised expertise. They are in addition to being complex, hard to maintain, and subject to data drift.
In this blog post, we will investigate:
- what the stakes of modern recommender systems are,
- how Devoteam G Cloud has successfully managed to create a reusable recommender system pipeline and
- how it could apply to your business.
In this blog post, we take a practical view from a project we implemented at the Royal Belgian Football Association. The RBFA is the official representative of Belgian football. They have many responsibilities ranging from managing the Belgian football teams like the Belgian Red Devils and Belgian Red Flames to assisting local teams with their organisation. In order to bring value for both the RBFA and their members, they wanted to build an algorithm capable of making personalised content recommendations based on the users’ behaviour to be used in their app and website.
What are embeddings?
In order to understand how recommender systems work, we need to define their main working entities: embeddings. Embeddings are high-dimensional vectors, mathematical representations of business entities. In the case of the RBFA, where the goal was to make content recommendations, Devoteam G Cloud has used embeddings for users and embeddings for the different types of content, mainly news articles, quizzes or videos.
The great aspect of embeddings is that, once they are constructed, you can easily make 4-ways recommendations based on the closest neighbours. Four-ways recommendations allow you to cover much more than just a simple content recommendation use-case. These are the possibilities it offers:
- Content to content: Similar content recommendations on a web page (“Users also viewed”).
- Content to users: Marketing targeting of users (“Newsletters”).
- User to content: Classical content recommendations (“Your newsfeed”).
- User to users: Users persona identification for marketing purposes (“User categorization”).
For the RBFA, the four recommendation ways were important, because they wanted to understand their users better, while also improving their overall experience. To this end, the RBFA is able to use their embeddings to serve more personalised content to their users, but also to create relevant newsletters and increase engagement.
As you can see, embeddings are much more than just a simple mathematical tool, they offer a complete solution that can help your everyday business on very diverse aspects.
Facing the two most common problems with embeddings: cold starts & data drift
The #1 problem of recommender systems: cold start
One general problem of recommender systems is that they face what we call the “cold start problem”. Each time a new piece of content is published, there is no user interaction with it yet. This makes it impossible for algorithms to know how to recommend the new piece of content.
Devoteam G Cloud has solved this problem for the RBFA by taking advantage of “tags”. Tags are small pieces of information that are manually linked to content by business people. Therefore, each time a user interacts with a piece of content, it also indirectly interacts with its tags. From there, since the content publishers work with a slowly evolving set of tags, it is much safer to directly make predictions on tags. This way, once a new content pops up, the information from the affinities of users with its tags makes it possible to include the new article in the content recommendations, even if the new article has no interactions yet. This discards the cold start problem completely as we can reuse the existing interactions between users and tags.
In practice, the cold start problem can also be observed for new users. In this case however the solution is much simpler. You can easily take the average of all the user embeddings, resulting in a user’s behaviour following the main trends of the application. Once the user has a minimum number of interactions with different contents, the system is able to switch to generating a personal embedding, allowing proper personalised recommendations.
The inevitable data drift
The above paragraph shows an important aspect of machine learning pipelines: data evolves in time. Of course, your data now will not be the same as your data in a week, a month, or a year. For this reason, everyone has to retrain their models every now and then, otherwise their recommendations will reflect poorly on the situation of their data now. To this end, Devoteam G Cloud has developed a pipeline that automatically retrains the current data, so that the model always keeps up with the latest trends.
Implementing powerful algorithms to understand the relationship between users & tags
To make a recommender system based on collaborative filtering (i.e. recommendations are based on users’ behaviour), we typically use matrix factorization on an interactions matrix. An interactions matrix is a large sparse matrix in which we store the importance of the interaction between a user and a tag.
For example, if the interaction type is content views, then we may sum up each time a user has seen a tag through any content. Then, matrix factorization (MF) handles how to generate the embeddings from the interactions matrix. Most importantly, MF ensures that by multiplying each user and a tag embeddings, the resulting score approximately corresponds to the interaction score between each user and tag pair.
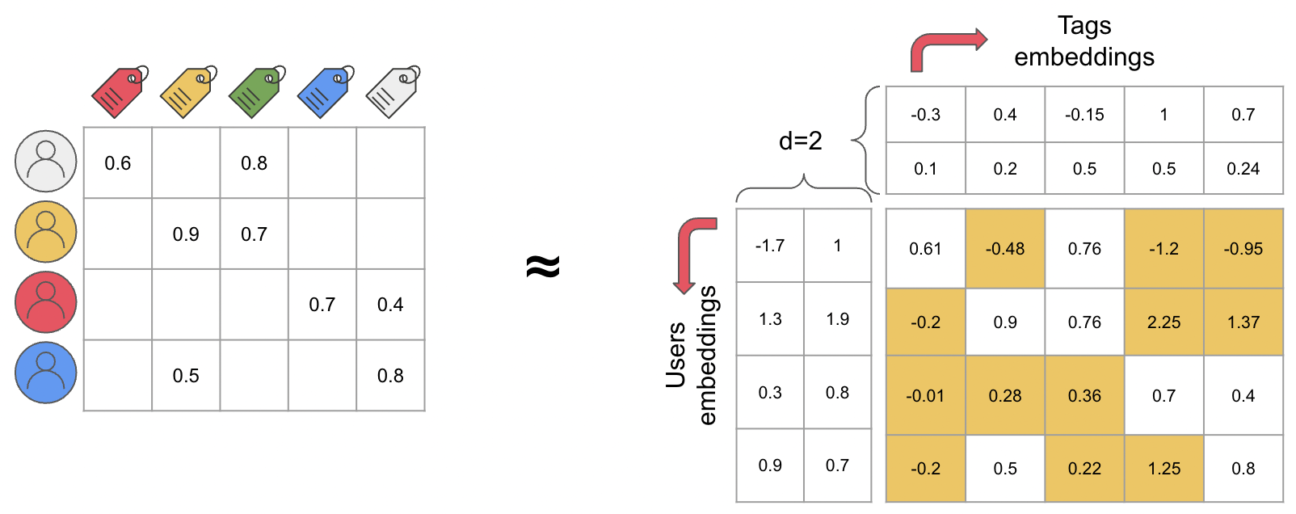
The truth is, there are tons of ways to apply matrix factorization, and each technique has its own advantages and disadvantages. Two examples of such techniques are:
- One purely statistical, based on Singular Value Decomposition (SVD);
- One deep learning-based, relying on a custom Neural Matrix Factorization architecture.
At Devoteam G Cloud, we are using both of these models depending on the specificities of our clients’ use-cases, allowing our solutions to better fit their needs. For the RBFA, we are using a custom SVD model, because it can be trained and deployed in no time, while requiring very little data.
Recommender systems in practice
As we have seen previously, the main problems of current recommender systems is that they require specialised expertise, are subject to data drifts, and suffer from the cold start problem.
That’s why Devoteam G Cloud has automated the recommender system pipelines and methods so that new use cases can be delivered into production very quickly. Of course, some specific problems may require specialised expertise to fine-tune the performance of the models.
Getting you up and running faster with Devoteam G Cloud’s ML Accelerator
This is why Devoteam G Cloud has developed its own tools on top of Google Cloud Vertex AI to make the processes efficient and less error-prone. From our battle-tested setup, we are able to decompose every step of the ML work (from data exploration to model monitoring, passing by experimentation and hyperparameter tuning), this will make sure that we develop the best possible solution for each business use-case.
As a conclusion, we have seen a high-level overview of how modern recommender systems work, and what constraints we have to take into account to achieve the best possible performance.
At Devoteam G Cloud, we developed our own Accelerator for automated recommender system pipelines, allowing us to invest the majority of our time in actually building machine learning models. In a next blog post, we will go more in-depth on how to apply MLOps principles to your machine learning project and how to successfully maintain production models.
Did this case inspire you? Then contact us or download the RBFA app to discover how it works from an end-user perspective.

