
In this article we will focus on industrialising the tagging of your data. You can see the action of tagging as adding metadata to your data. Having good metadata about your tables and fields is the first prerequisite to robust data governance. Only then you can start building new data governance layers such as automating the process around Personally Identifiable Information (PII). How to make sure your analytics database can systematically remove someone’s data if it is asked ? How to assure that this PII data is not accessible by anyone? These are some of the questions that you will only be able to tackle in case you have sound metadata on your tables and fields.
Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway.

If there’s anything that’s defining successful businesses today it’s the successful understanding, use, and strategy of a company’s data. In every company, data keeps growing at an exponential rate. While this could lead to an increased amount of insights, it often leads to companies being lost in this huge swamp of data.
And for the right reasons, as scaling to terabytes or petabytes of data requires some strong data governance to make sense of it all.
For the last 2 years we have been working on various data warehousing projects on Google Cloud and on the data governance of these projects. The mix of BigQuery coupled with Data Catalog makes it very efficient to govern the data of your whole organisation through a single pane of glass.
Data Catalog & BigQuery
Data Catalog being a resource at organisation level, it will allow you to access the data for all your projects through a single point of access.
By default all the schemas of your BigQuery tables will appear there. Hence it fulfils a visibility requirement needed by one of the data governance pillars.
Tag templates in Data Catalog
Data Catalog really shines with its taggings possibilities through tag templates.
With these templates, you define a template of tags that you can then fill in for any of your BigQuery tables, and fields within any tables.
Examples of tags at fields level can be:
- has_pii (boolean): boolean stating the existence or not of PII
- description (string): an explicit description
- classification (enumerates): the type of data this field contains (id, financial, scientific, etc.)
- etc.
You can easily come up with a dozen tags that will make searching and understanding your data much easier for all your data and business analysts.
Automated tagging in Data Catalog
Manual tagging process in Data Catalog
One drawback of Data Catalog when you start having many tags and a lot of data is that the tagging process can be quite time-consuming and not very convenient if you do it via the UI. Also, not only one person should be responsible for tagging.
A data steward would probably need to discuss the creation and changes to the tags with the data owner beforehand, and then create the tags manually in the GCP console.
Wouldn’t it be great if this process could be simplified and industrialised? This is exactly what we solved by creating a UI layer in the name of Google sheets on top of Data Catalog.
A solution for automating the tagging process with Google Sheets
With our tagging solution, a data steward can easily post tags in bulk to Data Catalog, only with the use of Google Sheets. Through the use of some Apps Scripts, we automatically load all BigQuery schemas with current tags into Google Sheets. Then it’s up to any data stewards to start tagging the data massively.
Once they are done tagging, clicking on an Apps Script “save” button will trigger an approval process that will send an email to a data owner for review. The data owner can then review all the changes through a web application hosted on App Engine. In case he/she agrees with the changes, the new tags are then posted to Data Catalog.
Architecture of our tagging PII data in Google Sheets solution
A summarised architecture of this process can be seen below. The real architecture involves some Cloud Functions for collection and validation of the data, an App Engine service for approval or rejection process, Datastore for saving the keysets etc.
The only tools that you need to interact as a user though, is the Google Sheet and the App Engine to approve or reject the changes in the tags.

Behind the scenes, a lot more happens to make this whole process robust. Below is a full architecture of all the Google products used:
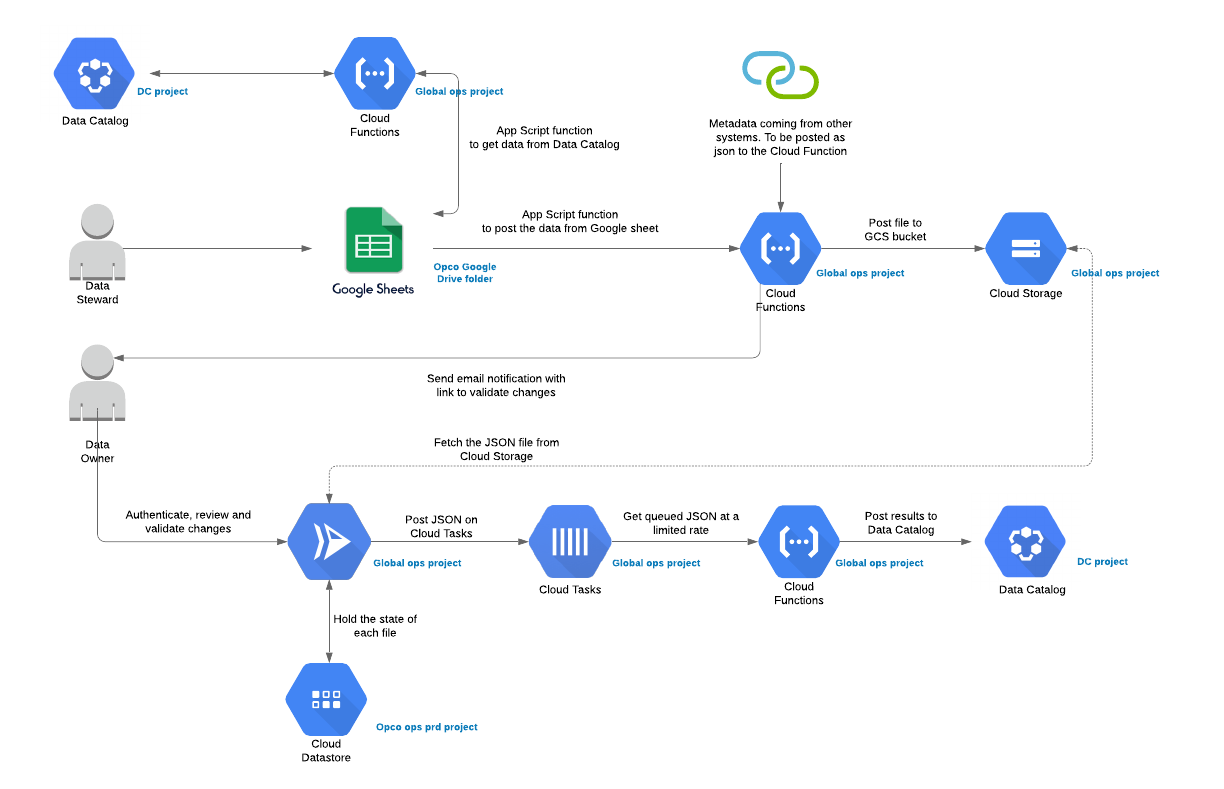
There are three main parts in this architecture:
1. The tagging via Google Sheets: a data steward is required to input a series of tags for all the data (table and column level) through a Google Sheet that will then post the tags to Data Catalog after the acceptance of the data owner.
To avoid manual mistakes, we have added some drop-down menus in the Google Sheet that gives you an easier overview of the values that you need to fill in to the tags. Some data validation processes are also done in order to check your changes before sending them to the data owner. Two functions are present in the Google sheet:
- Refresh data: this will call a Google Cloud Function that will fetch the latest tags from Data Catalog for all your data.
- Save data: this will save all your tags in a json file on Cloud Storage and at the same time sends an approval request to the data owner.
2. The approval process: This part is a simple web application hosted on App Engine and accessible via IAP for authorised users. A data owner can review the tags on this web app and in case he/she approves the changes, a simple “approve” click will then dispatch all the tags to Cloud Tasks.
3. The posting of the tags: one task on the Cloud Tasks queue corresponds to one BigQuery field. The handler of this queue is then a Cloud Function. This allows us to leverage a multitude of invocations for each of the tasks, and pay only for the few milliseconds each function invocation is running.
Conclusion
Google Cloud offers an incredible analytics suite and it’s of major importance to use it with strong governance, in order to protect and give visibility on the data. This article focused on industrialising your tagging process via Google Sheets on top of Data Catalog.
In a next article we will see how you can automate the encryption and decryption of your PII data through BigQuery’s built-in AEAD function together with Data Catalog.
Questions about this great way of starting with data governance, or about any other data & analytics challenge? We’re happy to discuss the best way forward with you!
How to save tons of time & resources by accelerating your data & analytics strategy? Read more about our data warehouse accelerator Flycs!

