
Machine learning operations (or MLOps) is a key aspect of ML engineering which aims to simplify AI lifecycle from the beginning to its end. It is built on the concept of DevOps to add pieces that are specific to its domain. DevOps combines every tasks of a software system to provide a high quality and shortened development lifecycle. It then enables teams to deploy new features and finish projects faster. MLOps aims to apply those principles to Machine Learning, although in this case we have new ML-specific components to consider. The goal is to enable continuous development and deployment of models and to ensure proper monitoring and management. This should happen fast and secure in order to eliminate toil from the daily job of Machine Learning Engineers and Data Scientists.
2.1 Towards a reusable deployment pipeline
At the core of MLOps is the deployment pipeline. Without it, ML engineers would have to manually deploy models every time, which is error prone and time intensive. Instead, models should be deployed automatically based on the code and available data. However, many things should be considered when setting up an MLOps pipeline. This will be covered in the following sections.
2.1.1 Pipeline components
In essence, a pipeline is a series of steps or components that are executed in a specific order and which pass inputs and outputs to each other. In most cases, components are Docker containers that execute a specific script. Each component should have a clear task that it per forms, for instance transforming input data, training a model, deploy ing a model, etc.
Output produced by components is often referred to as artifacts. These should be tracked across different pipeline executions so it can be traced back what artifacts were used as input for a model running in production.
2.1.2 Pipelines
A pipeline is a series of multiple components chained together to automate a set of tasks. In ML related terms, this most often resembles the following example:
- Fetch training data
- Split into train, validation and test set
- Perform feature engineering on training data
- Train model
- Evaluate model
- Deploy model if evaluation is good
All of this is fully automated and any output from each of these steps is tracked in a Metadata Store. Of course pipelines can differ from this example, but they will generally follow this structure.

Figure 2: A simple example pipeline
One important distinction to be made is the one between a pipeline template and a pipeline execution. To enable re-usability, a pipeline should be defined in a pipeline template, which takes specific inputs and produces specific outputs. This should make it easy to run the same pipeline on different datasets and with different parameters. A pipeline execution is one run of the pipeline template with specific input parameters. A pipeline template is most often defined in a programming language like Python (which is then rendered into a static file) or a static file format like YAML or JSON.
2.1.3 Version Control System
Any team working on code together benefits from having it stored in a Version Control System (VCS). Going into the details of a VCS is out of scope here, but it plays a crucial role in proper MLOps practices.
Code for feature engineering, model training, etc. should all be versioned to enable easy rollbacks etc. One tool should get specific attention here and that is the Jupyter Notebook. Jupyter Notebooks are very popular among data scientist for doing quick experimentation and data exploration. This is a useful feature to have, however Jupyter Notebooks have an important pitfall which is that they do not encourage modularization of code. This makes them unfit for any code that makes it into production.
It is therefore recommended to move any code that needs to go into the deployment pipeline into proper Python (or other programming language) files following coding best practices. These files then go into the Version Control System where they will trigger the building of artifacts.
2.1.4 Building and storing artifacts
The build artifacts in this section are different from the pipeline artifacts described above. Build artifacts are objects generated from a specific version of the code stored in the VCS. Traditionally this is done through a CI/CD pipeline which takes the code defining the pipeline templates for example and pushes static files representing the template to an artifact registry.
The CI/CD pipeline starts whenever a new version of the code is pushed to the VCS and generally includes the following steps:
- Test code: it is important to perform testing on any code that will be pushed into a production system. There are multiple different types of tests:
– Unit tests: these tests test a small part of the code like one function with a specific input
– Functional tests: check that one application is behaving as expected (e.g. the model hosting service)
– Integration tests: test that an entire integrated system is behaving as expected (e.g. the application stack interacting with the model service) - Build artifacts: static artifacts are generated from the code. For MLOps systems, this mostly corresponds to:
– Components: build Docker containers or files describing com ponent behavior
– Pipeline templates: build pipeline templates from code - Push artifacts: after artifacts have been built, they are pushed to a registry. This is where they are stored with a specific tag and can then be fetched at runtime to perform one pipeline execution.

Figure 3: A simple CI/CD pipeline
2.1.5 An end to end example
Chaining CI/CD and the training pipeline together provides a full end to end workflow. This is where MLOps enables ML teams to effectively experiment with different approaches and deploy models easily. For the ML engineer working, this flow looks like the following:
ML Engineer works in local development environment (Jupyter Notebook, Python in IDE, R, …)
Once experimentation is done, the ML engineer ensures their code is properly structured and has good test coverage
The ML engineer checks in their code with the remote VCS
The new version of the code triggers the CI/CD to build and push new artifacts (pipeline templates, component Docker containers, …)
Either the CI/CD pipeline immediately kicks off the pipeline run or the ML engineer triggers this manually.
The ML pipeline then prepares the training data, trains and evaluates the model and pushes it to an endpoint.
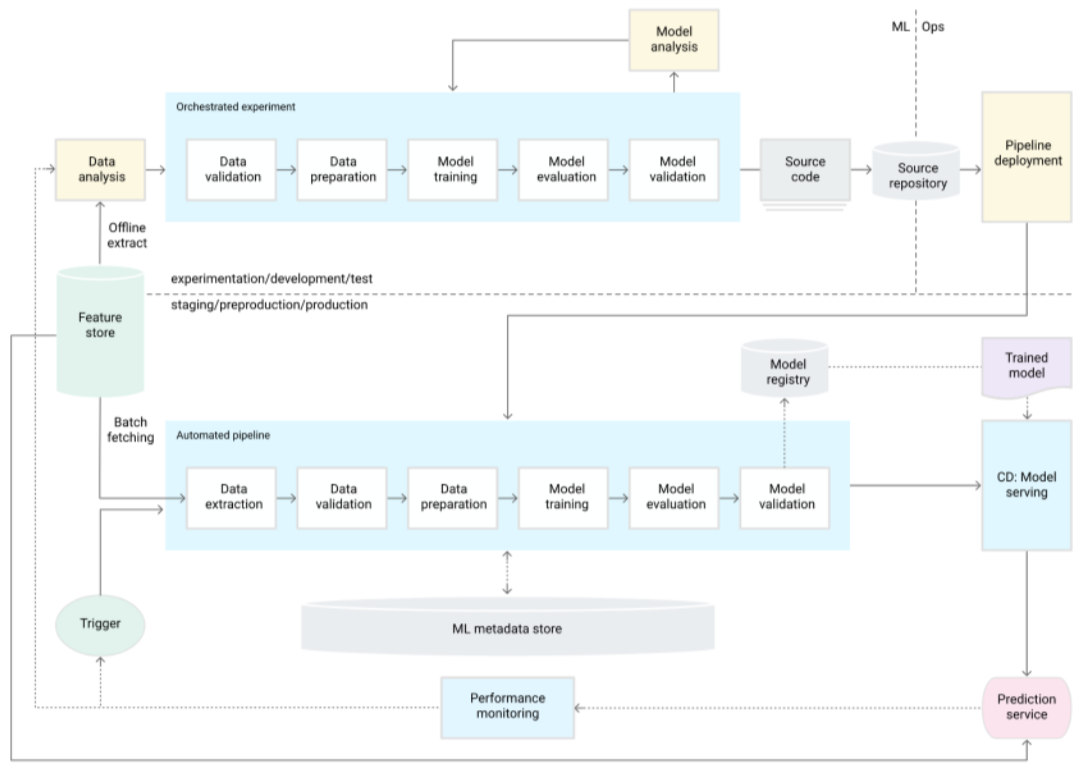
Figure 4: An end to end pipeline example.
Following this flow ensures the entire process is repeatable and enables the ML engineer to reuse artifacts across environments. It also eliminates a lot of the manual work of the engineer and can take extra steps towards automation such as saving artifact metadata to the metadata store, automating monitoring, coordinating experiments, etc.
2.2 The Feature Store
A Feature Store is a key component in MLOps. It consists in a cen tralized repository that stores and manages features used in machine learning models. These features can be raw data, preprocessed data, or derived features that have been created during the feature engi neering phase. The main goal of the feature store is to enable data sharing within the organization.
It typically includes several key features, such as:
- Data store: It stores and manages features in a structured format.
- Data access: It provides APIs and other interfaces for data scientists and engineers to easily access and retrieve features for use in their models.
- Data lineage: It tracks the lineage of features, including where they came from and how they were processed.
- Data catalog: It allows data scientists and engineers to easily discover and search for features based on various criteria, e.g. feature names, data types, source systems, etc.
- Data versioning: It applies versioning capabilities to the features and allows to rollback to a previous version if needed.
- Data governance: It allows to implement data governance policies, e.g. data validation, data security, access controls, etc.
- Data monitoring: It can monitor for feature drift
- Automation: It can be integrated with other MLOps tools to automate the feature engineering, feature extraction, feature selection, and feature transformation.
- Feature serving: It can be customized to meet different model consumption needs, i.e. batch or real-time predictions.
Features within a feature store should be designed to be used by multiple models and pipelines. They should be a representation of the different business entities in the company.
2.3 Environment management
Deploying new models and code directly into a production environ ment is never a good idea. The chance of having a service interruption and as a consequence drop of revenue is something to be avoided. This is why it is recommended to have multiple environments to test changes in. Most companies will have at least three environments:
- Development (DEV): This is where ML Engineers run their experiments, develop model APIs and do all their testing.
- User Acceptance Testing (UAT): As the name suggests, this is where a select number of end users tests the model outputs to ensure they make sense in the context of the application they will be used by.
- Production (PROD): The live environment. This is what the end users of the model will see and interact with.
When working with different environments, it is important to decide how to move something from DEV to UAT and from UAT to PROD (this is often called “promoting” to the next environment). In the most basic setup, this could be done manually by an engineer. It is easy to see how this can lead to errors during the manual process, which can lead to service interruptions.
Instead, this should be automated. A popular concept of relevance here is called GitOps, where interactions with the VCS drive the changes in the environments. Using this principle, a basic workflow can be constructed for development and promotions of models.
- ML Engineer checks in code on a feature branch. A feature branch is a branch meant for working on a specific feature, so could be a new model, enhancement of a new model, …
- Artifacts are built by the CI/CD pipeline
- ML Engineer runs pipelines and experiments to train a new model and does the first round of testing
- ML Engineer merges his code to a shared development branch meaning his feature is ready for release
- Development is merged into the release branch which deploys the trained model into the UAT environment
- A select group of end users performs a round of testing to vali date model output
- If the model validation is done, the code is merged into the production branch (often called main). This triggers deployment of the model into production.
2.4 Monitoring of deployed models
2.4.1 SLAs, SLOs and SLIs
Once a model has made it into production, it is important to be notified of any service interruptions or degradations. Traditionally this is discussed in terms of SLAs, SLOs and SLIs:
- Service Level Agreement: A Service Level Agreement or SLA is a contract put in place between a service provider and service consumer, which states objectives to be met for the service being provided. These are often very similar to the SLOs defined below, but less strict (SLOs should be breached before SLA).
- Service Level Objective: A Service Level Objective or SLO is a specific objective relating to one performance measure of the service being provided. Typical examples of this could be:
– Availability: The service should be available 99.99% of the time over 12 months
– Accuracy: The model should have an accuracy of 80% - Service Level Indicator: A Service Level Indicator or SLI is an attribute that is being measured to determine whether or not the service level objectives are being met. Examples are:
– Service Uptime Percentage
– Model accuracy
– Latency
– …
2.4.2 Meeting SLOs
In order to meet the SLOs that were set, SLIs need to be measured and alerts need to be sent out promptly if there they fall below a certain defined threshold. Which measures need to be set up will be defined by the SLOs. A practical example of this could be:
The team has set an SLO to have an average latency of 20ms
To achieve this, the team is logging every call made to the service and every response from the service
A metric is defined as the time between request and response
When the team notices latency being longer than 20ms, they get an alert and investigate immediately to resolve the issue as soon as possible
When setting SLOs, it can also be useful to count in an error budget. An extra barrier of safety to serve as a buffer, this can be seen as the buffer between the SLO and the corresponding requirement in the SLA. Having this buffer, will also allow to account for planned downtime. Which is a good practice as it can help identify systems that rely too heavily upon each other to function. For example, the entire website should keep working, even when the recommender system is down.
2.4.3 Measuring Model Performance SLIs
One very common problem with measuring ML performance is the absence of specific metrics at inference time. The reason for this is that the “correct” value is not present at inference time. Some examples:
- A model that predicts next months’ revenue, will only know the actual value the month after
- A model that recommends a product to buy, will only know if it was correct on checkout
This means that there is a need for a feedback loop, where correct values are fed back to the monitoring system to create metrics on model correctness. This can often prove challenging, but is vital to assess model performance. More on this is discussed in section 3.6.
2.5 Monitoring for Model Drift
In the ML business, it is common to see constant changes in the environment that can dramatically impact the predictive accuracy of machine learning models. This concept is well known and is called model drift. It refers to the fact that model performance is degrading compared to what it predicted during the training phase. Out of this main drift derives the concept drift, meaning there’s a shift in the relationship between your models input(s) and output(s). A common example is the covid-19 which drastically changed the consumer behaviours, all kinds of social/economical data and therefore lots of patterns that may have been trained to be recognized by ML models. Secondly, we have data drift that can occur when the statistical properties of your input or output data change. This problem happens oftenly for input features/variables used to train the model or even for labels (also called label drift). The main reasons why we have feature drift are wide but can often be related to changes in the data sources or in the data processing layer. On the other side, label drift is mostly caused by the changing distribution of your output.
Following section 3.4.3, model performance degradation should always be monitored for. However at this point, degradation has already taken place and there was a measurable impact on the end user of the service. This impact can be lessened by monitoring for input data drift as well. It will allow the ML engineer to detect issues sooner. To achieve this, one has to examine the distribution of a specific feature over a sliding window of time and perform a statistical analysis to determine whether the distribution has changed. If data drift is detected, the techniques in section 3.6 should be applied to keep the model up to date.
2.6 Keeping models up to date
Keeping models up to date is one of the big challenges ML engineers face. As discussed above, model drift can cause performance degra dation to models running into production. The good news is that re training a model should not be a big challenge. This comes back to the pipeline template mentioned in section 3.1.
Following the approach described above, any model running in production will have been created by a pipeline run and every run will have been associated with a specific pipeline template. In theory, re training is then as simple as creating a new run of the pipeline tem plate, but providing a new dataset with more recent data.
When this should be triggered depends on the use case, SLO and budget. The simplest solution is to retrain on a fixed schedule, but that is hard to trace back to the actual SLO that was defined. This is why it is common to trigger a retraining either based on model performance degradation or input feature drift. This way a model can be retrained only when needed.
Another approach is to take into account the fact that data dis tributions might change at the start of model development. Online learning approaches, allow ML Engineers to design models that learn at runtime. This can be a good choice when data volatility is high or datasets are too big to be used efficiently for training.
2.7 Infrastructure as code
Now that the components of an MLOps system have been identified, it is important to think about how those components need to be set up. This is where Infrastructure as Code (IaC) is vital. The principle of IaC is that all infrastructure should be defined in code, not created manually through scripts or a UI. This has a multitude of benefits:
- Versioning of infrastructure: just like application code, infrastructure as code can be versioned. This means it can then be promoted across environments just like discussed before. Infrastructure is first applied in dev, then uat and lastly prod. On top of this, rollbacks are also easy as engineers only need to apply a previous version of the infrastructure code.
- Disaster recovery: things out of the engineers control can hap pen (a datacenter going down, someone with permissions they should not have removing something manually, …). This is when having the entire infrastructure in code is extremely valuable. It allows engineers to spin up a new instance of the environment relatively quickly.
- Reusability: specific parts of the infrastructure as code (modules) can be reused in order to replicate existing infrastructure for new environments or models.
Common tools used for Infrastructure as Code are Terraform, Ansible, etc. They enjoy broad community support and are running in production at many companies over the world. In the case of the system described above, the major components that need to be included in IaC would be:
- The VCS system (can be self hosted): with its repositories, groups and access policies.
- The CI/CD pipeline: depending on which technology is used, it might be necessary to create runners for the CI/CD pipeline.
- The artifact registry: the artifact registry serves for storing pipeline templates and Docker containers. There are many options for this either open source or from different cloud providers.
- The pipeline runner: the pipelines need compute to be able to run training and data processing jobs. The most common plat form for this is some flavor of Kubernetes.
- The model registry: when a model has been trained, it needs to be stored somewhere so it can be deployed later. This is the model registry. The most basic version of this is a blob store where the model is stored as a file.
- The serving infrastructure: models need some form of computer to run on. This can be a virtual machine (VM), Kubernetes or some serverless offering from a cloud provider.
- Monitoring & alerting: there are many options for monitoring and alerting infrastructure. In general, it includes some way to collect logs and metrics, alerting policies and notification channels.
- Re-training infrastructure: as mentioned in section 3.6, it is important to be prepared to retrain models. This infrastructure of ten includes some sort of scheduler and will probably reuse existing training infrastructure.

