About Deliverect
Deliverect is a Belgian scale-up, founded in 2018 that is taking the restaurant industry by storm. Deliverect helps restaurants process their online orders directly from their registry so they don’t have to worry about all the dedicated tablets and different applications that each and every delivery service requires.
By providing restaurants with a unified view for all big delivery services like Deliveroo, Uber Eats and Shopify, restaurants can increase their online presence, lower the time spent on managing different services and receive unified reporting out of the box. This product is such a time saver that it is no wonder that Deliverect already helps restaurants worldwide and even recently acquired the unicorn status, for which we want to congratulate them again!
The outcome of Deliverect’s collaboration with Devoteam G Cloud
After only a couple of months of closely working together with the data team of Deliverect, we shifted the old analytics environment to a newer version that enables collaboration, drops cost, enables standardised models and automatically generates documentation. All key features of an analytical platform that put Deliverect into the position to further leverage the data to provide a better product to its customers and support them in their mission to “be the backbone of on-demand food and help businesses to connect with their customers & help them to thrive online”. In the sections below we’ll dive deeper into how exactly we achieved this result together.
The problem
To keep up with such a fast growing business it is important that decision makers can make the right, informed, decisions and can make them fast. To spot all the important trends as they are happening, Deliverect pushes data from various sources to Google BigQuery and interprets the data with Looker dashboards.
This first data warehouse iteration has served its purpose but was not able to scale at the same pace as the growth of the company. With more and more data linked to BigQuery, Looker models became increasingly complex and in the end no longer maintainable by the Looker developers.
The core of the problem was that there was no data modelling layer in BigQuery. This meant that Looker developers could only work with data in its raw format coming directly from the sources. Similar data coming from different platforms can have a very different structure which makes it hard to combine, just ask anyone working with Google Ads, Facebook Ads & LinkedIn Ads in the same dashboard.
Devoteam G Cloud was able to adapt to our needs as a fast growing company where changes to the plan are expected almost on a daily basis. They brought both the hands-on and the expert knowledge to help us find the best architecture and make sure we implemented it in the right way.
The goals
With the creation of the new analytics platform, Deliverect had multiple goals. The first goal was scalability. Data engineers and Looker developers should be able to work at the same time on different pieces of the data or dashboards without interfering with each other. This setup is important when scaling the engineering teams to not be bottlenecked by one or multiple people.
The second goal was to provide a standardised data model in BigQuery. The purpose of this model is to shield the specific data structure of the various data sources and ingestion tools as they most likely change over time. Another benefit of a good data model is that other tools, like Vertex AI, can now very easily connect to clean data without having to spend a lot of time again on data modelling.
The third goal was to lower the operational cost of the overall analytical environment. Because data was dumped into BigQuery by various ingestion tools, it was not partitioned and clustered according to how Deliverect was using the data. This resulted in queries that accessed a lot more data than actually needed which increased the cost and lowered the performance without providing actual value.
The last goal is data discoverability. This means that anyone (with access) should be able to get a clean overview of what data is available together with descriptions and tags. This is needed to decouple the data users from the data engineers. When such an overview is provided, data users can quickly check what data is available, what the fields mean and where they originate from.
The methodology and results
Goal 1: Working together
Together with the data team of Deliverect, we decided to create the data warehouse using the open source framework dbt core. Dbt stands for data build tool and helps developers to define, run and test SQL transformations in code. The advantage of defining the SQL transformations in code is that it makes it easy to integrate with various Git workflows to help developers work together on the same data warehouse.
While dbt core ships a lot of features out of the box, it also needs quite some extra steps to make it ready to run a production environment. Luckily for Deliverect, they have the required know-how in-house (shout-out to Antonio Curado of the Deliverect data team) so they felt confident to maintain the infrastructure.
Using dbt core together with a git workflow that allows engineers to quickly try-out new features in their own sandbox made it very easy to collaborate. Multiple developers can work on multiple features at the same time without fearing to break something in the process.
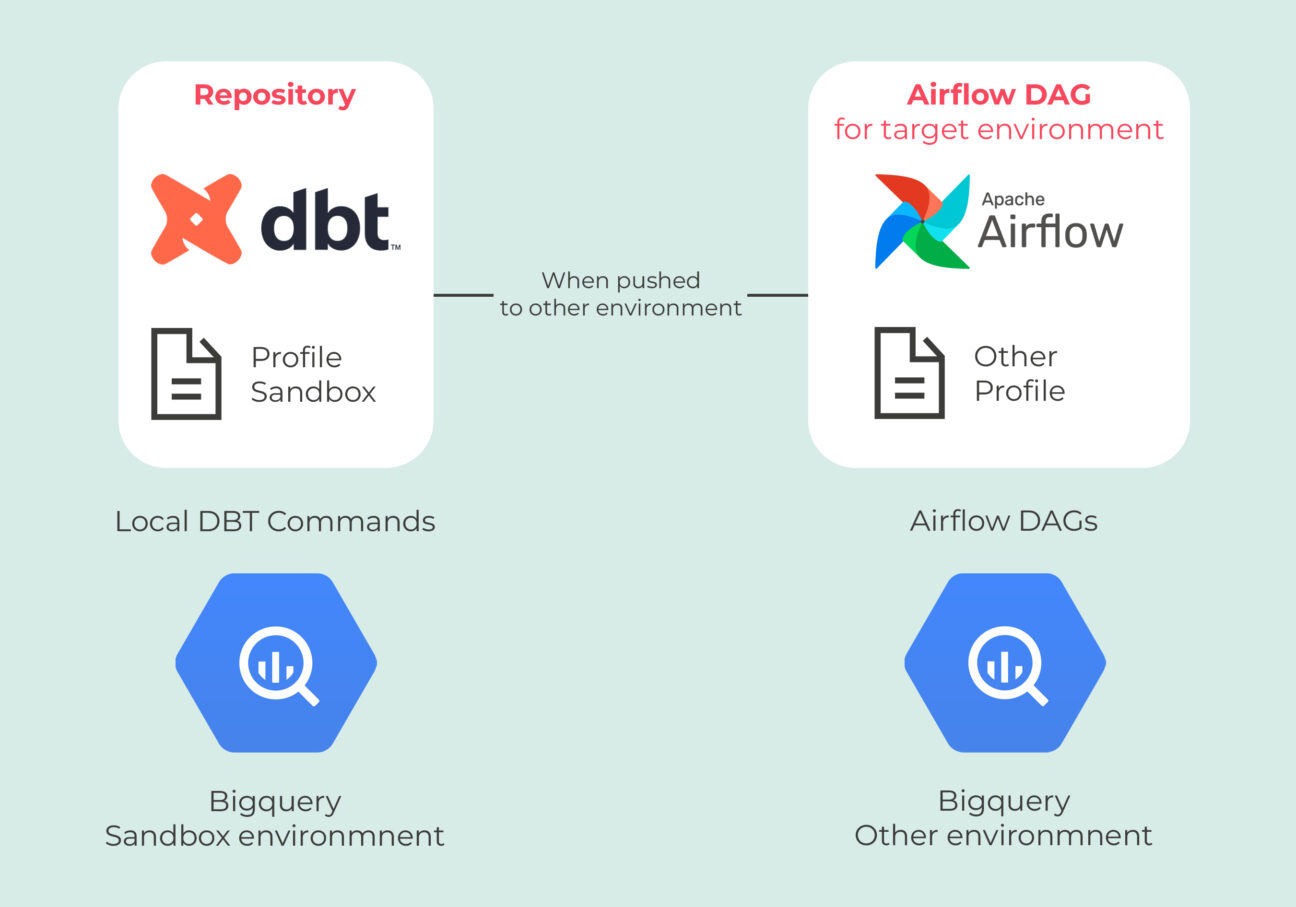
On the Looker side, the biggest change was to start using extensions of Looker views to define custom logic instead of adding for example custom metrics directly to the Looker generated view from BigQuery. The reason why this change helps the Looker team is that now, when new columns or descriptions are added in the underlying BigQuery table, they can just generate the Looker view automatically from the table again without having to redefine all the custom logic. This makes it easier to work together because developers can safely and automatically load in more columns without having to know what all the other custom logic means.

Goal 2: Standardised data model
To help the creation of a standardised data model, we recommended Deliverect to use a multi-staged data warehouse setup with a landing zone for data, a data warehouse and curated data marts.
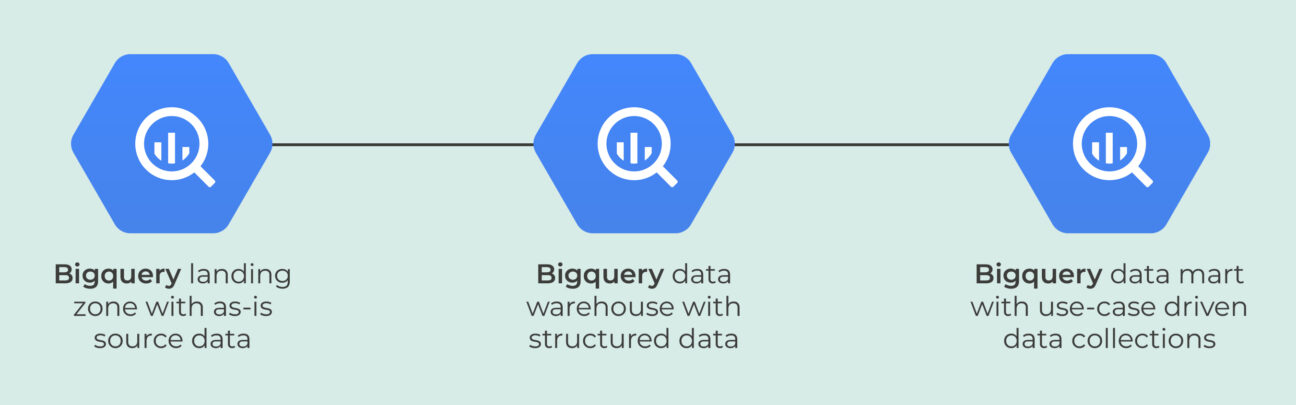
The landing zone, or base layer, will collect all the data from all the data sources in the format that is used by the data supplier. The data warehouse uses this raw data and transforms it into a data warehouse schema that represents the way business talks and thinks about the data. It is also created in such a way that tables are very maintainable and can build up historical data and changes if required. The data mart layer, the last layer of the three, will grab all required data from the data warehouse and supply downstream applications with data in required formats with optimal partitioning and clustering settings. All transformations needed are created in dbt and synchronised with the help of Airflow.
Goal 3: Lower operational costs
Deliverect was at the time of the project using the on-demand pricing model of BigQuery that is based on the amount of data accessed by queries. This means the more data you ask, the more you have to pay. Luckily BigQuery supports the partitioning and clustering of tables to lower the amount of data accessed and thus lowering the overall bill.
While this exercise is still an ongoing process, we had very good first results on some important costly queries. A data engineer of Deliverect, reported that he implemented partitioning on one of the big tables and dropped the cost of a particularly costly query with 99.5%.

We dropped cost of an important but costly query by 99.5%
Goal 4: Data discoverability
To solve the lacking self-service discoverability of data we leveraged dbt’s auto documentation generation feature and put it on steroids. Dbt core ships with a feature to generate a static website containing data descriptions, lineage, tags, code and other metadata fields that are useful for data users.
We created a CI/CD pipeline that serves the site for all Deliverect employees. This lowers the amount of questions to the data team so they can focus on developing features.
The Github Action we created for this also used a keyless authentication procedure to lower operational toil of rotating service account keys and to nullify the risk of leaking service account credentials in the open. A strategy we recommend to implement everywhere where possible. More information about this implementation is available in this blogpost.
We took this CI/CD pipeline and showed it to the infrastructure team as an example on how to perform keyless integrations to increase security.
Do you want to discuss your own data & smart analytics project with us?

Get in touch with
Mark De Winne
Google Cloud Business Developer at Devoteam G Cloud

