
Article rédigé par Valentin Coudert, GCP (Web & AI) Presales Engineer
Ces dernières semaines, j’ai tendance à exagérément parler de mes dernières vacances à la Réunion, et cela doit aussi se ressentir dans mes recherches Google !
Par exemple, savez-vous comment couper un ananas correctement ?
Quand vous tapez cette recherche dans Google, vous pouvez tomber sur une vidéo mise en avant dans les résultats de recherche (un extrait optimisé, ou featured snippet). Mieux encore, Google peut vous indiquer directement le passage le plus pertinent de la vidéo !
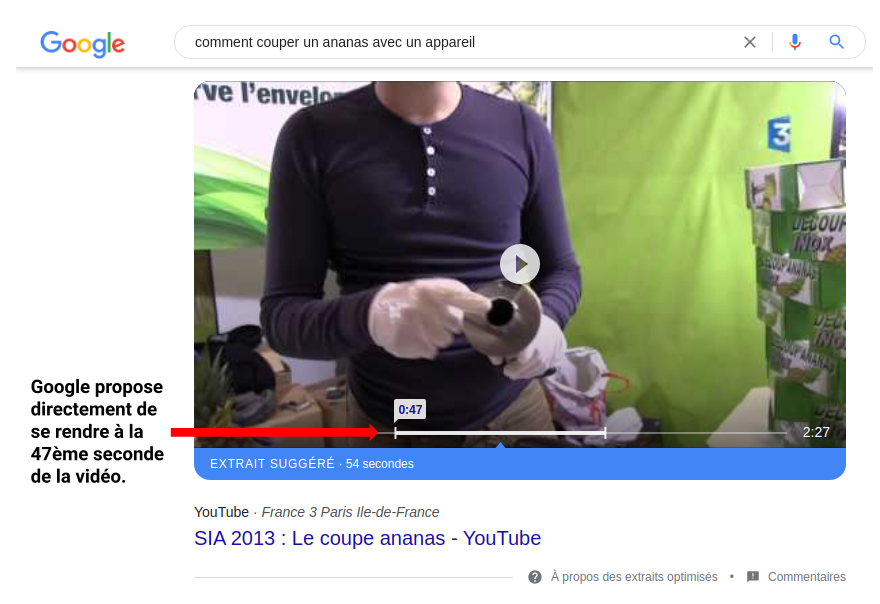
Que vous faudrait-il pour proposer un comportement similaire sur votre propre site web et ainsi faire coup double: mettre en valeur le contenu de vos vidéos et améliorer l’expérience utilisateur ?
⇒ Du machine learning pour comprendre votre contenu + un bon moteur d’indexation et de recherche + une interface utilisateur adaptée.
Dans cet article, nous ne traiterons que la première partie : mettre en place les bons services de Google Cloud (et cela inclut du machine learning) pour extraire le contenu des vidéos, le comprendre et le mettre à disposition d’un moteur d’indexation. C’est parti !
Prenons le parcours utilisateur attendu

- L’utilisateur tape sa recherche. Nous pourrions imaginer une étape de compréhension de sa requête (qu’il écrirait en langage naturel) mais pour simplifier, nous allons imaginer une recherche par mots-clés.
- Sa requête est traitée par le moteur de recherche qui va sélectionner parmi toutes les vidéos qu’il connaît celles contenant des passages correspondent aux mots-clés.
- La ou les vidéos sont retournées à l’utilisateur, avec des liens rapides vers les extraits en question.
Comment bien indexer une vidéo ?
Le moteur de recherche ne va pas pouvoir, à chaque requête utilisateur, étudier le contenu des vidéos et décider lesquelles sont pertinentes. Cela prendrait des heures pour répondre. Il faut plutôt qu’en amont, au moment où la vidéo est rendue disponible au moteur de recherche, l’association entre celle-ci et les mots-clés qui la caractérisent ait été faite. C’est ce qu’on entend par comprendre la vidéo.
Quelles sont les composantes d’une vidéo que l’on pourrait utiliser pour la comprendre:
- des métadonnées (titre, auteur, date de la capture, langue, durée…) : ces informations sont directement indexables et sont déjà utilisées par de nombreux systèmes informatiques pour organiser et répertorier vos vidéos, comme le fait le système de fichiers de votre ordinateur
- des images: une suite d’images qui forment le contenu visuel de la vidéo
- des sous-titres: potentiellement intégrés ou non directement dans les images de la vidéo, ou dans un fichier à part
- du son: musique, dialogues, bruits d’ambiance, ou bruit tout court
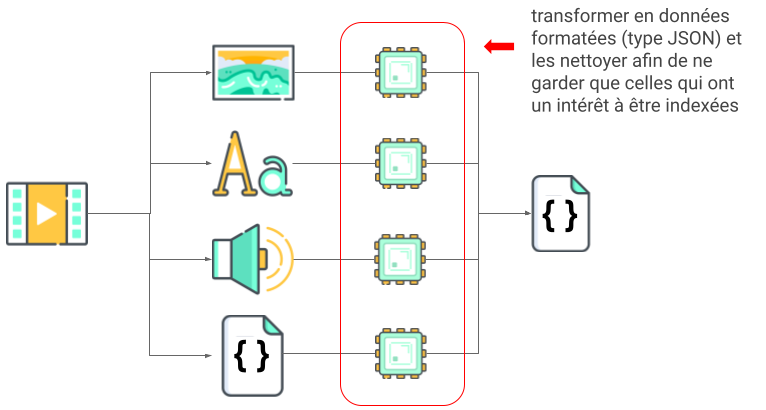
Ce qu’il ne faut pas oublier, c’est l’objectif initial: il faut non seulement sélectionner les bonnes vidéos pour répondre à l’utilisateur, mais aussi trouver les passages pertinents à l’intérieur de la vidéo. C’est-à-dire savoir à quel moment le mot-clé a été vu/prononcé/écrit.
Google Video Intelligence API
La plateforme Google Cloud a une API bien pratique, Video Intelligence API, pour notre cas d’usage puisqu’elle embarque plusieurs outils en un:
- elle peut extraire l’information de ce que l’on voit (véhicules, animaux, personnalités, logos de marques, objets…)
- elle peut extraire le texte visible à l’image (grâce à l’OCR – sous-titres incrustés, noms de rue…)
- elle peut transformer les dialogues en texte (Speech to Text)
Concrètement, comment fait-on ?
Il y a plusieurs manières d’appeler cette API: REST, gRPC ou via une librairie cliente. C’est cette dernière option que nous préférons dans nos projets clients car elle gère les mécanismes d’authentification et de réessai en cas d’erreur.
Pour le besoin de l’article cependant, nous utiliserons l’outil en ligne de commande gcloud et éviterons ainsi d’avoir à coder (il est déjà installé si vous passez par Cloud Shell, c’est du temps de gagné !). Nous allons travailler sur un extrait vidéo tiré d’une présentation interne que je donnais à notre équipe commerciale, sur les briques de Machine Learning justement.
La vidéo.
Note: j’utilise la version “alpha” de l’outil gcloud car toutes les fonctionnalités ne sont pas encore présentes dans sa version standard. Par contre, via API REST ou gRPC, tout est bien disponible en v1.
Detect-labels

Afin de détecter les labels au sens large, c’est-à-dire les objets, les concepts, visibles durant la vidéo.

(je ne mets volontairement qu’une partie des résultats car le fichier est assez long)
Le retour, en JSON, nous permet d’avoir la description de ce qui a été détecté (un logo), sa catégorie s’il en a une (élément graphique, au sens large), et quand il a été détecté (le logo est visible tout du long).
Les résultats de l’appel detect-labels sont vraiment variables suivant le contenu de la vidéo. Dans le cas d’une présentation (l’enregistrement d’un Google Meet ici), ce n’est pas le plus intéressant, mais s’il se passait plus de choses sur la vidéo, vous auriez plus de détails.
Detect-text

Extraire le texte de la vidéo, grâce à la reconnaissance optique de caractères (OCR)

On peut voir quel texte est présent dans la vidéo. L’OCR délimite les extraits textuels ligne par ligne, c’est pourquoi un paragraphe ne sera pas retourné en entier mais séparé pour chacune de ses lignes.
Les métadonnées associées sont la localisation dans l’image (avec les coordonnées des quatres coins) et la durée durant laquelle le texte est visible.
Transcribe-speech

Retranscrire sous forme de texte le discours parlé de la vidéo, comme peut par ailleurs le faire l’API Speech-to-text.
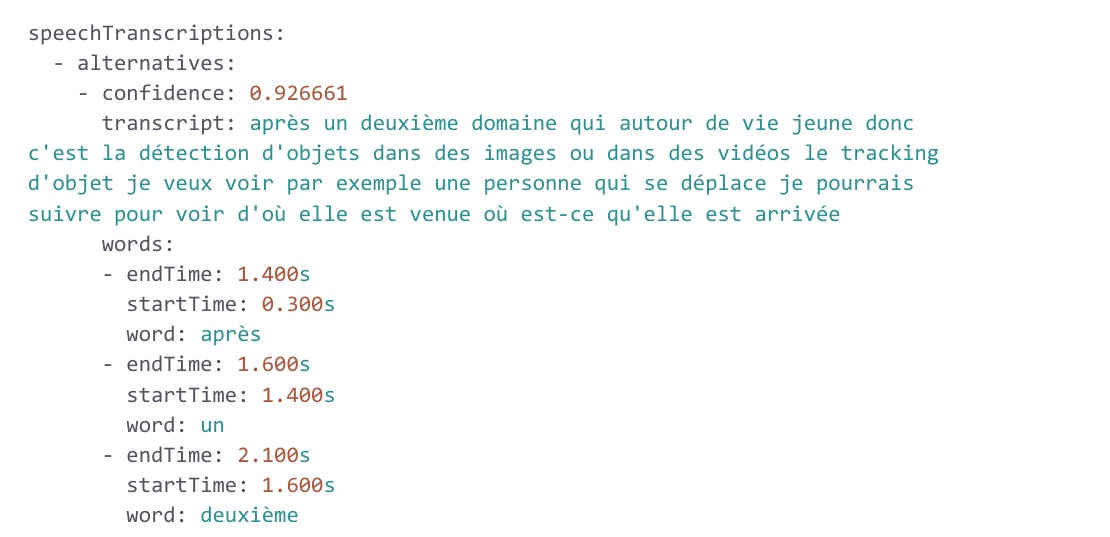
A noter que ce n’est pas du JSON qui est retourné par l’outil gcloud mais ce sera bien du JSON si vous utilisez les API REST ou gRPC.
Vous pouvez voir la retranscription complète du passage dans le champ transcript mais, plus intéressant si vous voulez créer des accès rapides à des parties précises de la vidéo, vous avez surtout pour chacun des mots (dans l’ordre) entre quel et quel instant ils ont été prononcés.
Natural Language API
Nous avons désormais un certain nombre d’associations entre du contenu textuel et l’instant auquel il a été vu, prononcé ou écrit dans la vidéo.
Soit le moteur d’indexation que vous allez utiliser est suffisamment intelligent pour faire lui-même le tri entre les termes qui ont un vrai intérêt et ceux qui n’en ont pas, soit vous pouvez lui mâcher le travail en passant par la Natural Language API.
Le but de cette API est de comprendre le langage humain, pour nous aider à le traiter de manière programmatique. Elle peut calculer le sentiment global d’une phrase (pratique pour un service client qui traite des réclamations) ou en extraire les entités principales (c’est ce qui nous intéresse ici).
N’ont de sens à être traités que les résultats qui proviennent de transcribe-speech et de detect-text car ceux de detect-labels sont déjà prêts à l’emploi.


Parmi les entités que l’API détecte comme importantes, on retrouve le texte “Google Cloud”, étrangement catégorisé dans le type “OTHER” (faites le test avec “Adidas” et ce sera catégorisé comme “ORGANIZATION”). Mais le fait d’avoir, pour cette entité, un objet metadata non-vide, et qui contient même un lien vers Wikipédia vous informe que cette entité a une certaine importance et qu’elle mérite certainement d’être indexée.
Une fois cette API utilisée sur tous les extraits textuels qui méritaient un petit nettoyage, vous n’avez plus qu’à construire l’objet final à indexer, dont le modèle correspond globalement à :
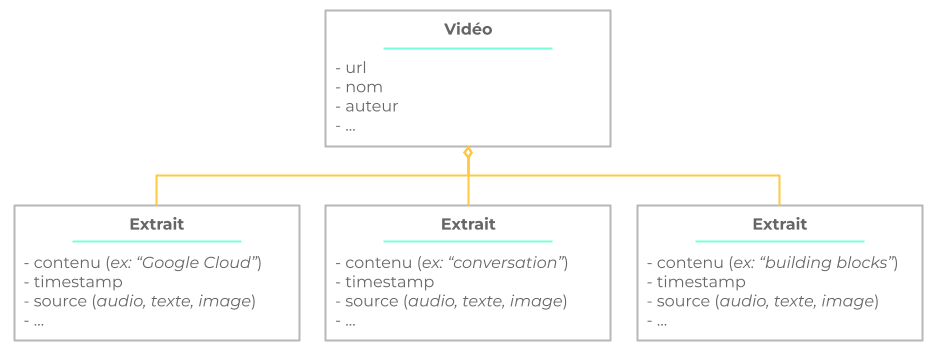
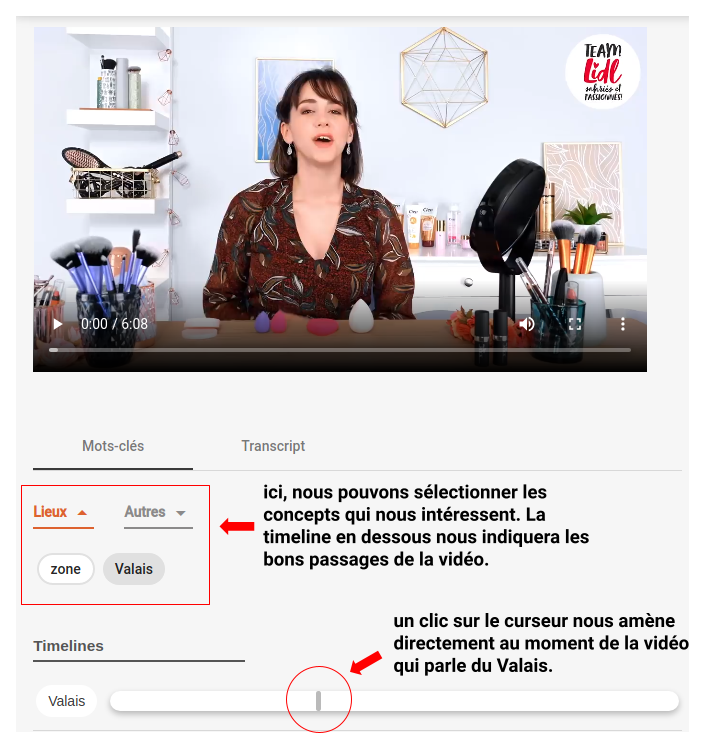
Vous avez désormais toutes les clés pour afficher, côté navigateur, un lecteur avec votre vidéo et des temps forts en fonction de la recherche de l’utilisateur.
Comme nous avons pu le faire sur une interface de démo chez G Cloud.
NB: tous les éléments présents dans cet article (vidéos, captures d’écran, schémas…) sont la propriété exclusive de Devoteam G Cloud et ne peuvent être utilisés ailleurs sans la permission explicite de l’entreprise et des personnes qui figurent dessus.

