Wat is een data lake?
Voordat we de vraag beantwoorden wat het beste data lake-platform op Google Cloud is. Het is belangrijk om eerst te praten over de definitie van een data lake en waarin het verschilt van een data warehouse.
Er zijn een paar data lake definities, maar voor dit artikel gaan we uit van de definitie die door Google opgesteld werd:
“Een data lake is een gecentraliseerde opslagplaats ontworpen om grote hoeveelheden gestructureerde, semigestructureerde en ongestructureerde gegevens op te slaan, te verwerken en te beveiligen. Het kan gegevens opslaan in zijn native formaat en elke variëteit ervan verwerken, zonder rekening te houden met beperkingen qua omvang.”
Verschillen tussen een data lake en een data warehouse
Met deze definitie in gedachten kunnen we de verschillen zien tussen een data lake en een typisch data warehouse.
- Een data lake host alle soorten gegevens en niet alleen gestructureerde gegevens zoals een data warehouse.
- Een data lake slaat gegevens op in het originele formaat dat het van de bron heeft gekregen en bijvoorbeeld niet in een enterprise data warehouse schema.
- Het laatste verschil is dat het datalake waarschijnlijk veel meer data zal hosten dan het data warehouse, dus het is nog belangrijker om gemakkelijk de opslagcapaciteit te kunnen opschalen.
Dus, waar moet ik mijn data lake maken?
Nu we een gemeenschappelijke definitie van een data lake hebben, kunnen we ons buigen over de vraag welk platform het beste is. Zoals met veel dingen in het leven hangt het antwoord op deze vraag af van de bedrijfscontext waarin je de vraag stelt. Heb je veel ongestructureerde gegevens zoals foto’s en video’s dan zullen je eisen anders zijn dan wanneer je veel gebeurtenissen en transactionele databases wilt verenigen.
Om dit artikel zo waardevol mogelijk te maken voor iedereen vergelijken we 3 Google Cloud Services (Cloud Storage, BigQuery, Cloud SQL) en laten we zien wat de sterke en zwakke punten zijn van elke dienst met betrekking tot de eisen van een goed data lake platform, zodat je kunt zien welk platform het beste werkt voor jouw bedrijf.
Als je de basis van deze diensten al kent, ga dan door naar het volgende deel. Voor degenen die een opfrisser nodig hebben leggen we hier Cloud Storage, BigQuery & Cloud SQL kort uit:
- Cloud Storage slaat gegevens op als ‘blobs’ (binaire grote objecten) binnen een ‘bucket’. Een blob kan van alles zijn (een bestand, video, afbeelding van een besturingssysteem…) maar u kunt alleen op de blob als geheel reageren. Je kunt bijvoorbeeld niet de eerste pagina van het bestand opvragen, maar alleen het hele bestand. Cloud storage werkt met een gedistribueerde storage engine zodat je gemakkelijk kunt schalen tot petabytes aan gegevens.
- BigQuery slaat gegevens op in kolomgeoriënteerde databasetabellen waar attributen worden gescheiden door kolommen. BigQuery werkt met een ontkoppelde storage- en rekeninfrastructuur, zodat u gemakkelijk tot petabytes aan gegevens kunt schalen.
- Cloud SQL slaat gegevens op in rij-georiënteerde databasetabellen waar attributen worden gescheiden door kolommen. Cloud SQL werkt niet met een gedistribueerde storage engine dus opschalen wordt een probleem als je boven de 1 TB uitkomt.
Gegevens moeten kunnen worden opgeslagen
Het begint allemaal met deze twee acties:
- Gegevens ophalen van waar ze worden geproduceerd en
- Gegevens op te slaan in het data lake-platform.
Hoewel je gemakkelijk een boek kunt schrijven over hoe je dit aanpakt, vind je hier een beknopte samenvatting:
Ongestructureerde gegevens
Als je ongestructureerde gegevens hebt, dan is de kans groot dat je iets gebruikt dat lijkt op Storage Transfer Service. Deze dienst kan van nature gegevens ophalen uit andere publieke clouds, bestandssystemen of URL’s. BigQuery en Cloud SQL zijn niet ontworpen om ongestructureerde gegevensobjecten op te slaan, dus ze zijn geen optie, zelfs niet als je dat echt zou willen.
(Semi-)gestructureerde gegevens
Als je (semi-)gestructureerde gegevens hebt die afkomstig zijn van API’s of databasetabellen, is de kans groot dat je werkt met een ETL-tool zoals Datastream, Fivetran of Airbyte om gegevens in jouw data lake te laden. Veel van deze tools kunnen zowel data as-is naar BigQuery als naar Cloud Storage pushen, maar ik raad aan te kiezen voor BigQuery. De reden daarvoor is simpel: gegevens in BigQuery zijn veel gemakkelijker te visualiseren, te beheren en te gebruiken. Daar komt bij dat het direct synchroniseren van gegevens in BigQuery de noodzaak wegneemt om aangepaste code te schrijven om gegevens te verplaatsen van jouw data lake in Cloud Storage en jouw data warehouse in BigQuery.
Als je snel veranderende gestructureerde gegevens hebt, is het soms zelfs het beste om een leesreplica van jouw operationele database in Cloud SQL te maken in plaats van te vertrouwen op een andere datareplicatietool om jouw gegevens in BigQuery synchroon te houden. Waarom? Deze manier van repliceren kan goedkoper zijn dan het gebruik van een andere tool zoals Datastream wanneer de gegevens in jouw database veel veranderen. Het prijsmodel van deze Change Data Capture (CDC) tools is meestal gebaseerd op het aantal rijen dat wordt gerepliceerd naar een andere bron, dus veel veranderingen betekenen veel kosten.
Op gebeurtenissen gebaseerde gegevenspunten
Het laatste datatype zijn de datapunten die worden gepubliceerd in de vorm van gebeurtenissen. Deze gebeurtenissen kunnen gemakkelijk worden opgevangen door PubSub en direct worden opgenomen in BigQuery. Je kunt de events ook opslaan in Cloud Storage als je een Streaming Dataflow pipeline gebruikt. Maar nogmaals, data in BigQuery is een stuk makkelijker om mee te werken dan data in Cloud Storage, dus ik adviseer je om de BigQuery route te volgen.
| Kind of data | Get data | Store data |
|---|---|---|
| Unstructured | Storage Transfer Service | Cloud Storage |
| (Semi-) structured | Datastream, Fivetran, Airbyte.. | BigQuery |
| structured, highly volatile | Cloud SQL replication | Cloud SQL |
| Event based | PubSub to BigQuery, Dataflow | BigQuery |
Gegevens moeten vindbaar zijn
Als de eindgebruikers van jouw analytics tool de gegevens niet kunnen vinden, dan houdt het hele verhaal op. Het openstellen van een interface om gemakkelijk naar gegevens te zoeken is misschien geen vereiste voor een data lake-platform, maar het moet ten minste in staat zijn om zijn metadata bloot te stellen aan een ander framework voor gegevensbeheer dat in jouw organisatie wordt gebruikt.
Cloud Storage slaat gegevens op als blobs in buckets. Meestal worden gerelateerde gegevens in dezelfde bucket of submap binnen een emmer opgeslagen om het toegangsbeheer te vergemakkelijken. Na verloop van tijd verzamel je veel blobs en zul je merken dat het vrij moeilijk wordt om interessante objecten terug te vinden.
Het is mogelijk om een blob op naam te zoeken als je de naam kent en weet in welke bucket hij is opgeslagen, maar het is niet mogelijk om bijvoorbeeld alle blobs te krijgen die inkomstengegevens bevatten. Dit komt omdat Cloud Storage geen kennis heeft van de inhoud van zijn blobs, zoals de kolommen van een CSV-bestand. Het is mogelijk om metadata in te stellen op blobs in een bucket, maar helaas is deze informatie niet beschikbaar in Google Data Catalog, dus je hebt andere 3rd party services nodig om deze data bloot te stellen aan eindgebruikers. Maar wees voorzichtig, niet alle data catalogussen ondersteunen Cloud Storage.
Het weergeven van metadata uit BigQuery is daarentegen heel eenvoudig. Alle grotere data governance platforms kunnen metadata uit BigQuery lezen en soms zelfs uit de BigQuery job logs afleiden. Bovendien werkt BigQuery niet met gegevensobjecten maar met tabellen, zodat het zelfs mogelijk is naar een specifieke kolom te zoeken zonder de exacte naam van de tabel of dataset te kennen.
| Platform | Finding data will be… |
|---|---|
| Cloud Storage | Hard to scale |
| BigQuery | Easy |
| Cloud SQL | Easy if you put additional tools in place. |
Gegevens moeten veilig zijn
Wanneer je gegevens gaat delen en publiceren voor consumenten, moet je ervoor zorgen dat je niet te veel deelt! Tegenwoordig gebeuren de meeste datalekken via gestolen gebruikersgegevens. Vertrouw dus niet op de goede wil van jouw werknemers om alleen toegang te krijgen tot de gegevens waartoe ze toegang moeten hebben. Als hun inloggegevens worden gestolen, kunnen alle gegevens die zij kunnen zien, mogelijk worden gestolen of gelekt.
De toegangscontrole in Cloud Storage op bucketniveau werkt native met Cloud IAM. Dit betekent dat je dezelfde beveiligingsgroepen kunt gebruiken die je normaal gesproken gebruikt. Dit is een groot pluspunt omdat u geen extra groepen of gebruikersbeleid hoeft te beheren. U kunt ook meer gedetailleerde toegangscontrolelijsten (ACL’s) op blob-niveau definiëren, maar deze zijn moeilijker te onderhouden, dus Google raadt af om dit te gebruiken. Dit betekent dat mensen over het algemeen al dan niet lees- of schrijftoegang hebben tot alle inhoud van een specifieke bucket.
Toegangscontrole in BigQuery is zeer uitgebreid en werkt ook native met Cloud IAM. Je kan mensen toegang geven tot specifieke projecten, datasets (= verzameling tabellen), tabellen en zelfs specifieke kolommen binnen een bepaalde tabel. Je kan ook beveiliging op rijniveau toepassen en zelfs dynamisch jouw gegevens maskeren op basis van wie toegang heeft tot de tabel. Dit betekent dat je voor alle gebruikers in jouw organisatie tot op de rij en kolom in de tabel de toegang kunt beheren.
De toegangscontrole in Cloud SQL is gebaseerd op de toegangscontrole van de database-instantie die je draait. Als je bijvoorbeeld een MySQL-server draait, dan is het aan jou om gebruikers in de database te configureren. Dat is veel werk op schaal.
| Platform | Securing data will be |
|---|---|
| Cloud Storage | Easy to do at a granular level |
| BigQuery | Easy to do at all levels (granular & super detailed) |
| Cloud SQL | Hard to scale |
Gegevens moeten bruikbaar zijn
Nu mensen toegang hebben tot de gegevens en kunnen vinden wat ze willen, moeten we ervoor zorgen dat ze de gegevens ook efficiënt kunnen gebruiken. In dit deel bespreken we hoe mensen met de data lake data kunnen werken door de integratie met de meest gebruikte analytics tools van Google te bespreken: Google Sheets en Looker Studio.
Gegevensblobs in cloud-opslag moeten volledig worden gedownload en handmatig worden geladen in een Google Sheets of MS Excel telkens wanneer men toegang wil tot die gegevens. Vooral wanneer het laden enige voorbewerking (zoals het hernoemen van headers) of typeconversie vereist. Dit kan vrij omslachtig zijn en mensen worden het vrij snel beu. Looker Studio kan ook rechtstreeks verbinding maken met Cloud Storage, maar kan alleen werken met CSV-bestanden.
BigQuery integreert zowel met Google Sheets als met Looker Studio. In Looker Studio kun je eenvoudig verbinding maken met elke tabel waartoe je toegang hebt en in Google Sheets kun je direct gegevens van BigQuery uitvoeren en ophalen binnen een Google Sheet. BigQuery integreert ook met Vertex AI Workbench voor data science en AI doeleinden.
Looker Studio kan ook out-of-the-box verbinding maken met Cloud SQL, maar vereist het downloaden van gegevens en handmatige import om samen te werken met Google Sheets of Excel.
| Platform | Using data is… |
|---|---|
| Cloud Storage | Hard |
| BigQuery | Easy |
| Cloud SQL | Easy for dashboarding, hard for sheets |
Voldoen aan wet- en regelgeving
De afgelopen jaren hebben overheden strengere datavoorschriften opgelegd, zoals het recht om vergeten te worden. Dit heeft een directe impact op jouw data warehouse, maar misschien nog wel een grotere impact op jouw data lake. Data lakes slaan gegevens op in verschillende formaten en schema’s, dus zonder goede governance wordt het heel moeilijk om de gegevens te vinden die je moet verwijderen of maskeren.
Als je Cloud Storage gebruikt, kan je Cloud Data Loss Prevention (DLP) gebruiken om objecten in een bucket te scannen om gevoelige informatie zoals creditcardnummers en telefoonnummers te redigeren of te markeren. Je kan ook objectlevenscyclusregels gebruiken om een automatisch vervalbeleid voor jouw gegevens op te stellen als je ervoor wilt zorgen dat oude gegevensbestanden op tijd worden opgeschoond.
BigQuery werkt ook met Cloud Data Loss Prevention, ondersteunt ook expiratie op tabelniveau, maar gaat nog verder met expiratie op partitieniveau. Met deze methode kan je automatisch oude partities uit een tabel verwijderen zonder de rest van de tabel aan te raken. Een andere leuke functie is dat je de BigQuery transformaties kan gebruiken om bij te houden waar de gegevens vandaan komen, zodat je direct weet uit welke tabellen je bepaalde datapunten moet verwijderen.
Cloud SQL ondersteunt deze functies niet out of the box omdat het afhankelijk is van de gebruikte database om de gegevens te verwerken. Je kan het beste vooraf controleren of de database die je gebruikt (bijvoorbeeld MySQL) een beleid voor het verlopen van gegevens kan ondersteunen.
| Platform | Following data compliance rules is… |
|---|---|
| Cloud Storage | Doable but certainly not easy |
| BigQuery | Easy |
| Cloud SQL | Depends on the database |
Kostenaspect
Om de kosten te vergelijken gaan we ervan uit dat alle gegevens minstens één keer per maand worden geraadpleegd. Als gegevens langer dan 1 maand door niemand worden gebruikt, is het misschien niet de moeite waard om de gegevens over te dragen naar het data lake.
Cloudopslag is, op het moment van schrijven, geprijsd op €45/maand per terabyte aan gegevens van actieve opslag in de multiregio EU. BigQuery kost €19/maand per terabyte aan gegevens in de EU-regio. Cloud SQL is wat moeilijker in te schatten omdat een groot deel van de kosten gaat naar de infrastructuur die je nodig hebt om de eigenlijke queries uit te voeren, maar het is veilig om aan te nemen dat het minstens €500 per maand zou kosten om een actief datameer met 1 terabyte aan gegevens te ondersteunen.
| Platform | Data storage cost is… |
|---|---|
| Cloud Storage | Pretty cheap |
| BigQuery | Cheapest |
| Cloud SQL | Expensive |
Gegevens moeten op één plaats staan
Nu weet ik dat ik meerdere platforms heb voorgesteld om allerlei problemen op te lossen en volgens de definitie van Google zou een data lake één gecentraliseerde opslagplaats moeten zijn, dus hoe gaan we nu verder? Bereid je voor op wat database-magie in de vorm van federated queries, BigLake en objecttabellen.
Met federated queries kan BigQuery een database in Cloud SQL bevragen alsof deze gegevens in BigQuery staan, zodat we gemakkelijk de mooie interface van BigQuery kunnen gebruiken, maar toch Cloud SQL voor de zeer vluchtige nichegegevens. Federatieve query’s zijn iets langzamer dan query’s die alleen gegevens in BigQuery benaderen, maar dat is normaal gesproken geen zorg voor een data lake, het belangrijkste is dat de gegevens beschikbaar en actueel zijn.
Met BigLake kan je:
- Cloud Storage en BigQuery verenigen om in Cloud Storage levende data direct in BigQuery te bevragen.
- Met de recente introductie van objecttabellen kun je zelfs BigQuery queries uitvoeren op de gestructureerde metadata van ongestructureerde datablobs die zijn opgeslagen in Cloud Storage.
- Een ander leuk aspect van BigLake is dat het ook toegang heeft tot objecten die worden gehost in AWS of Azure.
Dus als we alle beste oplossingen samenvoegen, kan een geweldig data lake platform er ongeveer zo uitzien als de onderstaande figuur. Waarbij alle onderdelen hun specifieke rol hebben, maar het totale dataplatform wordt blootgesteld aan de eindgebruiker via 1 stabiele interface, de BigQuery interface.
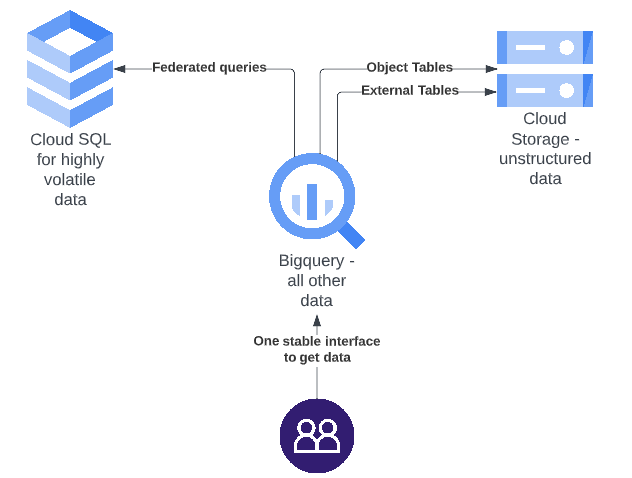
Conclusie
Samengevat: elke dienst heeft zijn unieke uitdagingen, voordelen en manier van werken, dus het is niet eenvoudig om één dienst te kiezen en daar bij te blijven. Gelukkig zag Google dit probleem ook in. Daarom hebben ze BigLake geïntroduceerd om ervoor te zorgen dat, ook als je meerdere diensten gebruikt om jouw gegevens op te slaan, je die ene interface niet verliest die nodig is om jouw data lake te beheren.
| Platform | Can handle … data | Data storage cost is | Following data compliance rules is | Using data is | Securing data will be | Finding data will be |
|---|---|---|---|---|---|---|
| Cloud Storage | Unstructured + structured | Pretty cheap | Doable but certainly not easy | Hard | Easy to do at a granular level | Hard to scale |
| BigQuery | structured | Cheapest | Easy | Easy | Easy to do at all levels (granular & super detailed) | Easy |
| Cloud SQL | structured | Expensive | Depends on the database | Easy for dashboarding, hard for sheets | Hard to scale | Easy, if you put additional tools in place. |
| -> Met BigLake kun je al die 3 opslagopties combineren, zodat je de beste optie kunt kiezen op basis van de gegevens die je hebt. |
Hoewel veel mensen pleiten om altijd Cloud Storage te gebruiken als data lake platform omdat het het enige platform is dat ongestructureerde data kan opslaan wil ik hier tegenin gaan. Hoewel Cloud Storage op zichzelf een geweldig product is en zeker het juiste platform voor sommigen, moet je nadenken over de beperkingen ervan. Het gebrek aan eenvoudige data governance, toegangscontrole op rij/kolomniveau en ingebouwde data processing engine is de reden waarom bedrijven als Deliverect hun data lake in BigQuery hebben gebouwd in plaats van in Cloud Storage.
Altijd Cloud Storage kiezen omdat de kans bestaat dat je soms met ongestructureerde data moet werken is als altijd een vrachtwagen besturen omdat je soms een koelkast moet vervoeren. Kies de vrachtwagen als je met grote objecten moet werken, maar maak in alle andere gevallen gebruik van BigQuery vanwege zijn gebruiksgemak, goedkope opslag en ingebouwde data governance.

Klaar om jouw data lake op GCP te bouwen?
Spreek met een Google Cloud-verkoopspecialist om de unieke uitdagingen waarmee je geconfronteerd wordt verder te bespreken.

