Over Deliverect
is een Belgische scale-up, opgericht in 2018, die de restaurantindustrie verovert. Deliverect helpt restaurants hun online bestellingen rechtstreeks vanuit hun register te verwerken, zodat ze zich geen zorgen hoeven te maken over alle speciale tablets en verschillende applicaties die elke bezorgdienst vereist.
Door restaurants te voorzien van een eenduidig beeld voor alle grote bezorgdiensten zoals Deliveroo, Uber Eats en Shopify, kunnen restaurants hun online aanwezigheid vergroten, minder tijd besteden aan het beheer van verschillende diensten en eenduidige rapportage out of the box ontvangen. Dit product is zo’n tijdsbesparing dat het geen wonder is dat Deliverect wereldwijd al restaurants helpt en onlangs zelfs de unicorn status heeft verworven, waarvoor we ze nogmaals willen feliciteren!
Het resultaat van de samenwerking tussen Deliverect en Devoteam G Cloud
Na slechts een paar maanden van nauwe samenwerking met het datateam van Deliverect hebben we de oude analytics omgeving overgezet naar een nieuwere versie die samenwerking mogelijk maakt, kosten verlaagt, gestandaardiseerde modellen mogelijk maakt en automatisch documentatie genereert. Allemaal belangrijke kenmerken van een analytisch platform dat Deliverect in de positie bracht om de gegevens verder te benutten om een beter product aan zijn klanten te leveren en hen te ondersteunen in hun missie om “de ruggengraat van on-demand food te zijn en bedrijven te helpen in contact te komen met hun klanten & hen te helpen online te bloeien”. In de onderstaande secties duiken we dieper in hoe we dit resultaat precies samen hebben bereikt.
Het probleem
Om zo’n snel groeiende business bij te houden is het belangrijk dat beslissers de juiste, geïnformeerde, beslissingen kunnen nemen en deze snel kunnen nemen. Om alle belangrijke trends te spotten terwijl ze zich voordoen, pusht Deliverect gegevens uit verschillende bronnen naar Google BigQuery en interpreteert de gegevens met Looker-dashboards.
Deze eerste data warehouse iteratie heeft zijn doel gediend, maar was niet in staat om even snel te schalen als de groei van het bedrijf. Met steeds meer gegevens gekoppeld aan BigQuery werden de Looker-modellen steeds complexer en uiteindelijk niet meer onderhoudbaar door de Looker-ontwikkelaars.
De kern van het probleem was dat er geen datamodelleringslaag in BigQuery zat. Dit betekende dat Looker-ontwikkelaars alleen konden werken met gegevens in hun ruwe formaat die rechtstreeks uit de bronnen kwamen. Vergelijkbare gegevens afkomstig van verschillende platforms kunnen een zeer verschillende structuur hebben waardoor ze moeilijk te combineren zijn, vraag maar aan iedereen die werkt met Google Ads, Facebook Ads & LinkedIn Ads in hetzelfde dashboard.
Devoteam G Cloud was in staat zich aan te passen aan onze behoeften als snel groeiend bedrijf waar bijna dagelijks wijzigingen in het plan worden verwacht. Ze brachten zowel de hands-on als de deskundige kennis om ons te helpen de beste architectuur te vinden en ervoor te zorgen dat we die op de juiste manier implementeerden.
De doelen
Met de oprichting van het nieuwe analyseplatform had Deliverect meerdere doelen voor ogen. Het eerste doel was schaalbaarheid. Data engineers en Looker ontwikkelaars zouden tegelijkertijd aan verschillende stukken data of dashboards moeten kunnen werken zonder elkaar te storen. Deze opzet is belangrijk bij het schalen van de engineering teams om niet in de knel te komen door één of meerdere mensen.
Het tweede doel was het bieden van een gestandaardiseerd datamodel in BigQuery. Het doel van dit model is om de specifieke gegevensstructuur van de verschillende gegevensbronnen en ingestion tools af te schermen, aangezien deze hoogstwaarschijnlijk in de loop van de tijd veranderen. Een ander voordeel van een goed datamodel is dat andere tools, zoals Vertex AI, nu heel gemakkelijk verbinding kunnen maken met schone gegevens zonder opnieuw veel tijd te hoeven besteden aan datamodellering.
Het derde doel was het verlagen van de operationele kosten van de totale analytische omgeving. Omdat gegevens door verschillende ingestion tools in BigQuery werden gedumpt, waren ze niet gepartitioneerd en geclusterd op basis van hoe Deliverect de gegevens gebruikte. Dit resulteerde in queries die veel meer gegevens opriepen dan eigenlijk nodig was, wat de kosten verhoogde en de prestaties verlaagde zonder werkelijke waarde te leveren.
Het laatste doel is de vindbaarheid van de gegevens. Dit betekent dat iedereen (met toegang) een duidelijk overzicht moet kunnen krijgen van welke gegevens beschikbaar zijn, samen met beschrijvingen en tags. Dit is nodig om de gegevensgebruikers los te koppelen van de gegevensingenieurs. Wanneer een dergelijk overzicht wordt verstrekt, kunnen gegevensgebruikers snel nagaan welke gegevens beschikbaar zijn, wat de velden betekenen en waar ze vandaan komen.
De methodologie en resultaten
Doel 1: Samenwerken
Samen met het datateam van Deliverect besloten we het datawarehouse te creëren met behulp van het open source framework dbt core. Dbt staat voor data build tool en helpt ontwikkelaars om SQL transformaties in code te definiëren, uit te voeren en te testen. Het voordeel van het definiëren van de SQL transformaties in code is dat het gemakkelijk te integreren is met verschillende Git workflows om ontwikkelaars te helpen samenwerken aan hetzelfde data warehouse.
Hoewel dbt core veel functies out-of-the-box levert, heeft het ook heel wat extra stappen nodig om het klaar te maken voor een productieomgeving. Gelukkig voor Deliverect, hebben ze de nodige know-how in huis (shout-out naar Antonio Curado van het Deliverect data team), zodat ze zich zeker voelden om de infrastructuur te onderhouden.
Het gebruik van dbt core in combinatie met een git workflow waarmee engineers snel nieuwe functies kunnen uitproberen in hun eigen sandbox, maakte het heel gemakkelijk om samen te werken. Meerdere ontwikkelaars kunnen tegelijkertijd aan meerdere functies werken zonder bang te zijn iets kapot te maken.
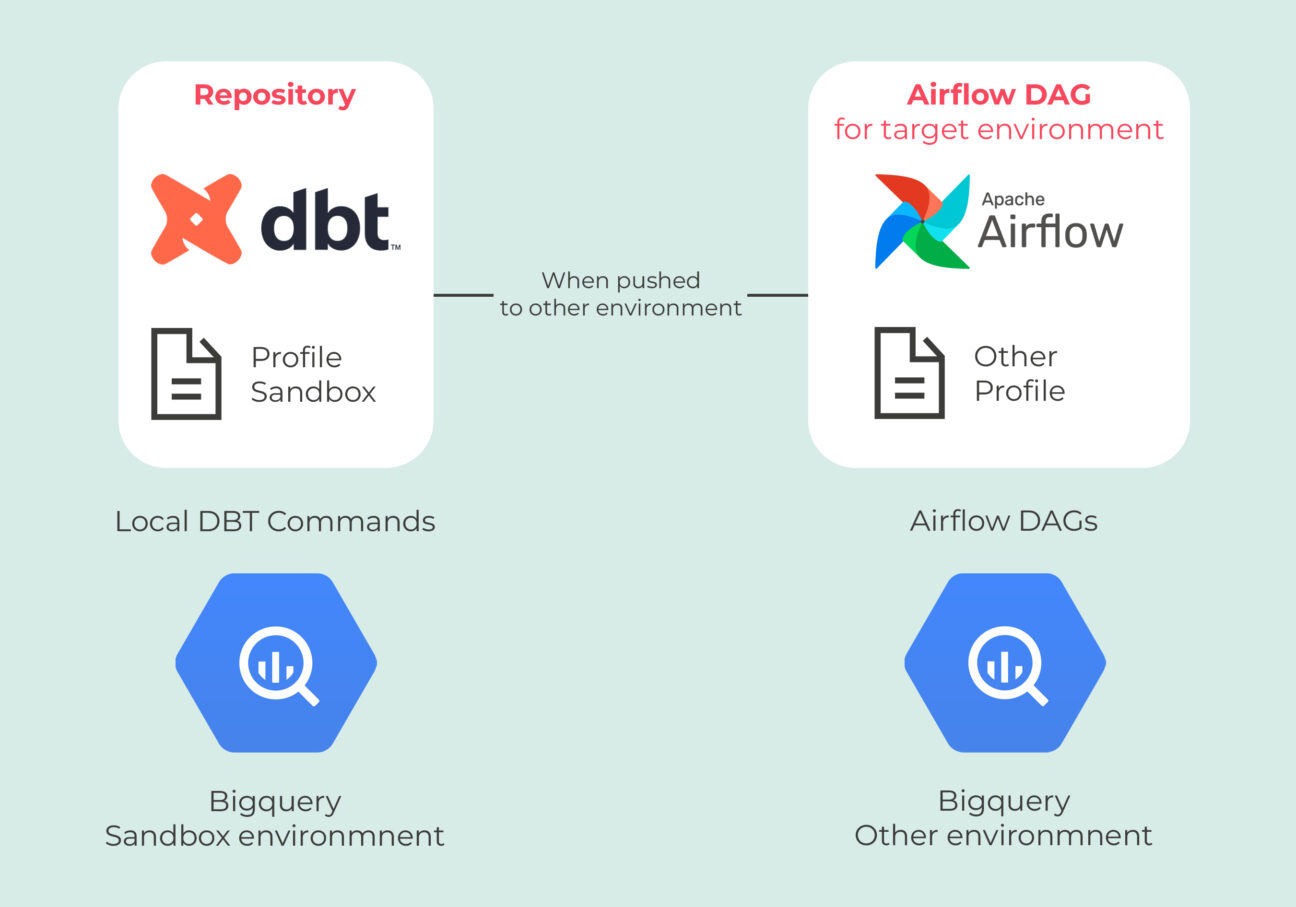
Aan de Looker kant was de grootste verandering om extensies van Looker views te gaan gebruiken om aangepaste logica te definiëren in plaats van bijvoorbeeld aangepaste metrics direct toe te voegen aan de Looker gegenereerde view vanuit BigQuery. De reden waarom deze verandering het Looker team helpt is dat nu, wanneer nieuwe kolommen of beschrijvingen worden toegevoegd in de onderliggende BigQuery tabel, ze gewoon de Looker view automatisch opnieuw kunnen genereren vanuit de tabel zonder alle aangepaste logica opnieuw te hoeven definiëren. Dit maakt het gemakkelijker om samen te werken omdat ontwikkelaars veilig en automatisch meer kolommen kunnen inladen zonder te hoeven weten wat alle andere aangepaste logica betekent.

Doel 2: een gestandaardiseerd datamodel
Om de creatie van een gestandaardiseerd datamodel te helpen, hebben wij Deliverect aanbevolen een multi-stage datawarehouse setup te gebruiken met een landing zone voor data, een data warehouse en gecureerde data marts.
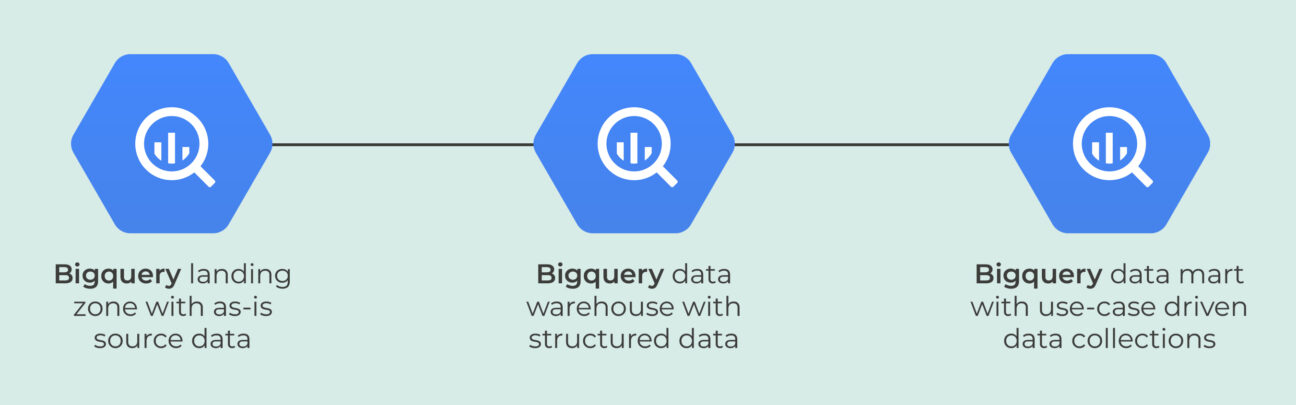
De landingszone, of basislaag, verzamelt alle gegevens uit alle gegevensbronnen in het formaat dat door de gegevensleverancier wordt gebruikt. Het data warehouse gebruikt deze ruwe gegevens en zet ze om in een data warehouse schema dat de manier weergeeft waarop de business over de gegevens praat en denkt. Het wordt ook zo gemaakt dat de tabellen zeer goed onderhoudbaar zijn en historische gegevens en wijzigingen kunnen worden opgebouwd indien nodig. De data mart laag, de laatste laag van de drie, haalt alle benodigde gegevens uit het data warehouse en voorziet downstream applicaties van gegevens in de gewenste formaten met optimale partitionering en clustering instellingen. Alle benodigde transformaties worden aangemaakt in dbt en gesynchroniseerd met behulp van Airflow.
Doel 3: lagere operationele kosten
Deliverect maakte ten tijde van het project gebruik van het on-demand prijsmodel van BigQuery dat gebaseerd is op de hoeveelheid gegevens die door queries worden opgevraagd. Dit betekent dat hoe meer data je opvraagt, hoe meer je moet betalen. Gelukkig ondersteunt BigQuery het partitioneren en clusteren van tabellen om de hoeveelheid opgevraagde gegevens te verminderen en zo de totale rekening te verlagen.
Hoewel deze oefening nog steeds een lopend proces is, hadden we zeer goede eerste resultaten op enkele belangrijke kostbare queries. Een data engineer van Deliverect meldde dat hij partitionering had toegepast op een van de grote tabellen en de kosten van een bijzonder kostbare query met 99,5% had verlaagd.

We hebben de kosten van een belangrijke maar kostbare query met 99,5% verlaagd.
Doel 4: Data discoverability
Om het gebrek aan self-service discoverability van gegevens op te lossen, hebben we de functie voor het automatisch genereren van documentatie van dbt gebruikt en op steroïden gezet. Dbt core wordt geleverd met een functie om een statische website te genereren met gegevensbeschrijvingen, lineage, tags, code en andere metadatavelden die nuttig zijn voor gegevensgebruikers.
We creëerden een CI/CD-pijplijn die de site voor alle Deliverect-medewerkers bedient. Dit verlaagt de hoeveelheid vragen aan het datateam zodat zij zich kunnen richten op het ontwikkelen van features.
De Github-actie die we hiervoor creëerden, gebruikte ook een verificatieprocedure zonder sleutels om het operationele werk van het roteren van serviceaccountsleutels te verminderen en het risico van het openlijk lekken van serviceaccountreferenties teniet te doen. Een strategie die wij aanbevelen om waar mogelijk overal te implementeren. Meer informatie over deze implementatie is beschikbaar in deze blogpost.
We namen deze CI/CD-pijplijn en toonden die aan het infrastructuurteam als voorbeeld voor het uitvoeren van sleutelloze integraties om de veiligheid te verhogen.
Wil je je eigen data & smart analytics project met ons bespreken?

Neem contact op met
Mark De Winne
Google Cloud Business Developer at Devoteam G Cloud

