
The Growing Data Challenge
Every year, the amount of data generated is increasing at an incredible rate. Within three years, it’s expected to reach 181 terabytes annually. But here’s the catch: most companies are struggling to find value in this vast amount of data. Infrastructure problems, such as data lakes turning into data swamps, slow systems, and unscalable stacks, hinder their ability to extract insights. Frustrations arise, leading people to rely on instincts rather than data. However, instincts alone aren’t enough. We need a solution that harnesses the power of data effectively.

The Evolving Data Landscape
In the past, a data platform consisted of a single database where data was stored and occasionally queried. But with the exponential growth of data, this approach is no longer viable. The current data landscape is complex and ever-expanding, with new technologies emerging frequently.
Do you feel lost when seeing this overview of data tools available?

It just shows that there are a ton of data tools out there and that the number of tools available is still increasing every year. Fun fact, there’s a game called “Big Data or Pokemon” that challenges you to distinguish between big data products and Pokemon names. This shows just how overwhelming the options have become. To navigate this landscape, we need a strategic approach for a modern data architecture.
The Modern Data Architecture
In the next sections we’ll discuss the several components that you can see in this high-level architecture schema:
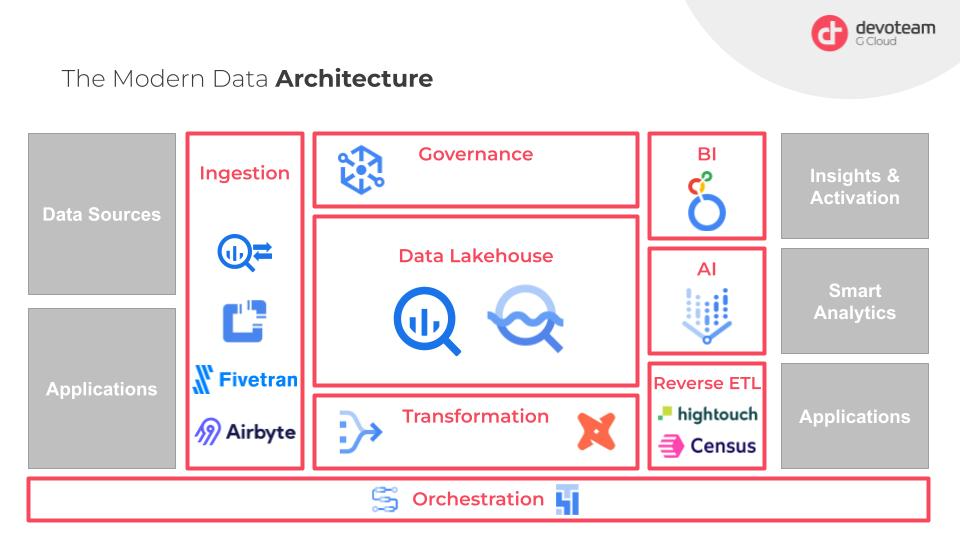
The Lake House Solution
Enter the concept of the lake house. It’s an open management architecture that combines the best of both worlds: the flexibility and scalability of a data lake with the data management and transactional consistency of a data warehouse. In simpler terms, it merges the power of blob storage (like Google Cloud storage) with BigQuery’s functionalities. This integration is where Big Lake comes into play. While not a separate tool, it enables you to leverage BigQuery’s capabilities on structured data stored in blob storage. It eliminates the need for redundant data storage and simplifies data access.
Simplifying Data Ingestion
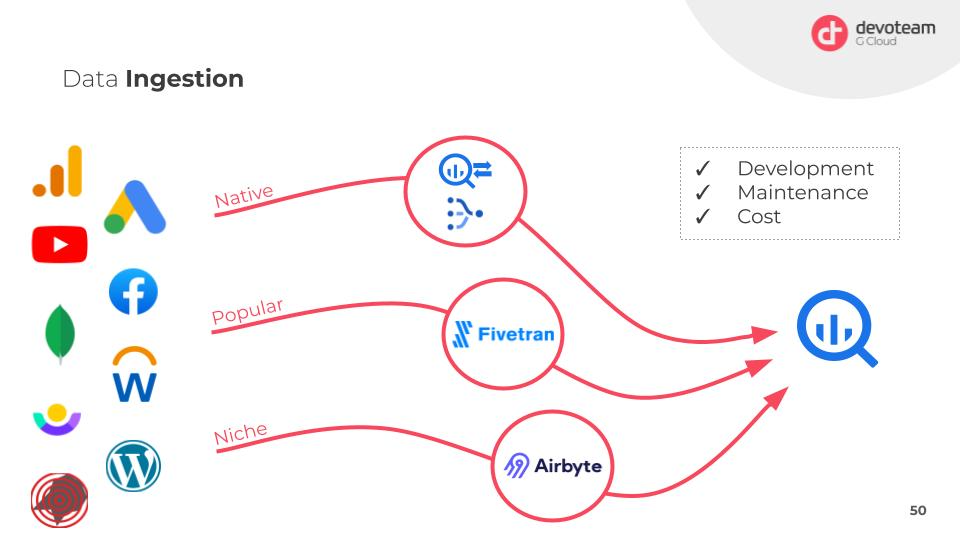
Data ingestion, though essential, is often a tedious and costly process. To make it more efficient, we can take three different paths: leveraging existing Google Cloud tools like BigQuery Transfer Service or Datastream, using managed services like FiveTran for non-GCP sources, or resorting to custom solutions for niche cases. The goal is to abstract away the complexities and reduce development and maintenance efforts. Each path has its trade-offs, balancing factors like ease of use, maintenance, and cost.
Streamlining Data Transformations
When data is ingested, it rarely arrives in the format needed for analysis. That’s where data transformations come in. The key is to enable self-service transformations, empowering your team to quickly prepare datasets for presentation layers like business intelligence tools or AI/ML applications. Two popular options for this are Dataform and dbt, each with its own strengths. Dataform integrates better with Google Stack, while dbt’s familiarity with Python appeals to teams with existing Python knowledge. Both tools offer data testing, version control, and data lineage capabilities, ensuring data quality and traceability.
The Power of Looker for BI and ML
In the realm of smart analytics, organisations often find themselves trapped in a common scenario: either the data department become the go-to source for insights, creating a bottleneck for information, or they witness the proliferation of siloed analytics, where teams replicate existing solutions without leveraging shared knowledge.
This predicament can be attributed to several factors, but in essence, it boils down to the absence of accessible tools. When organizations fail to provide user-friendly analytics platforms, like Looker, individuals naturally gravitate towards familiar solutions or rely on their peers’ recommendations.
In many other business intelligence (BI) solutions, regardless of the specific tool, organizations often face the need to implement an intermediate layer to feed data into these systems. Even if these tools support caching or storage options, the implementation of such layers becomes necessary. However, a significant drawback arises once this layer is in place – querying back to the original data sources becomes an arduous task, if not outright impossible with certain tools.
Enter Looker, a solution designed to bridge this gap effortlessly. With Looker, the aim is to minimise the effort required between data analysts and the underlying data layers created by the data engineering team. By adopting Looker, organisations enable their data analysts to focus on creating meaningful dashboards, while effortlessly accessing the data layers prepared for them.
The beauty of this approach lies in its minimal complexity. Looker facilitates a streamlined workflow, where data analysts can harness the power of the underlying data infrastructure without getting entangled in its intricacies. This seamless integration between analytics and data engineering paves the way for self-service BI, bringing together data preparation and insightful analysis in a user-friendly manner.
While the concept of Looker warrants further exploration and discussion, it serves as a glimpse into a world where organizations can empower their teams with easy access to analytics tools while leveraging the foundational data layers established by their data engineering counterparts. By eliminating bottlenecks and embracing self-service analytics, organizations can unlock the full potential of their data and drive meaningful insights across the enterprise.
The Power of Vertex AI
When it comes to AI projects, transitioning from creating machine learning models to production can be a significant challenge. That’s where Vertex AI comes in. Vertex AI offers the flexibility to use pre-trained Google models without the need for customization or platform migration. Whether you want to utilize Google’s models as they are, train custom models, or fully customize your AI projects, Vertex AI provides the core technology to fulfill your requirements. It’s a game-changer that simplifies the deployment and management of AI models.
Orchestration and Data Governance
Orchestration plays a vital role in tying everything together in your data architecture. It ensures that all individual jobs are executed in the correct order, preventing data ingestion issues and confusion. Two main tools for orchestration are Workflow and Airflow, each with its own advantages. Workflow is lightweight and cost-efficient, suitable for simpler pipelines. Airflow, on the other hand, is widely recognized and more suitable for complex scenarios, although it comes with higher hosting costs.
Data governance is often overlooked but crucial for effective data management. It involves ensuring data quality, accessibility, and security. Data security involves controlling access to sensitive data, while lifecycle management determines when data should be decommissioned. Additionally, data lineage helps trace the flow of data and quickly resolve any issues that may arise. Implementing a comprehensive data governance strategy is essential as your organization grows and more people access your data platform. So remember, it’s not always about the tooling, sometimes it’s just about the people.

The Importance of Cost Control and Observability
Controlling costs in data analytics is crucial, especially when running queries can become expensive. To mitigate this, setting up alerts and budgeting for projects can help monitor and prevent excessive spending. Additionally, incorporating observability as part of your governance strategy is essential. Observability allows you to track and analyze your data usage, costs, and performance, providing valuable insights for proactive cost control and optimization.
Conclusion: Creating a Robust, Modern Data Architecture
Building a robust data architecture requires addressing the limitations of traditional BI solutions, embracing the power of AI with solutions like Vertex AI, and implementing effective orchestration and data governance practices. By leveraging the right tools, streamlining integration, and establishing strong governance, you can empower your data analysts, simplify AI deployments, and ensure the quality, accessibility, and security of your data. Don’t overlook the importance of cost control and observability, as they play a crucial role in optimizing your data operations. With these strategies in place, you’ll be well-equipped to unleash the full potential of your data and drive meaningful insights and value for your organization.

