This article is written by Baptiste Wlodarczy, Cloud Data Engineer at Devoteam G Cloud
Google recently announced their entry into the Generative AI market, thus making it clear to the world that the likes of ChatGPT and MidJourney were not just a passing trend.

As the market for generative AI is expanding, it is becoming increasingly challenging to understand the various offerings. I came to realize this during a recent event in which a Google representative highlighted their pricing strategy’s advantage over OpenAI’s.
In this article, we will analyze the pricing strategies of both OpenAI and Google Cloud, focusing on their respective approaches to pricing their enterprise focused Large Language Models (LLM) solutions.
Disclaimer: This article is not a comparison of the different product’s capabilities. Its aim is to explain the two companies’ different LLM-related solutions and how they stack up against each other in terms of pricing. It should be noted that this article is not intended as a performance comparison.

Keep in mind that Google is still rolling out its Generative AI offering, which may explain the difference in complexity. Officially, Google’s comparatively late-arrival is due to the fact that they decided to package their offer as an enterprise-ready product from the very beginning, while OpenAI is working through GDPR compliance details as they roll out their product in different countries.
Each strategy has its own set of pros and cons: OpenAI arrived on the market earlier and established themselves as pioneers : every chat based Large Language Model is a “ChatGPT concurrent”, but this brought some legal controversies, like the temporary ban and subsequent reinstatement of ChatGPT in Italy. Google, on the other hand adopted a more cautious approach and arrived later, but avoided such legal issues.
Google’s self proclaimed advantage
The Mountain View firm’s superiority over OpenAI I referred to earlier would allegedly come from Google’s billing based on the amount of characters sent and received, while OpenAI’s billing is based on the number of tokens exchanged between the user and the model.
What I was told was that the character-based billing would benefit some languages such as French or German.
But wait: don’t french and german use much more characters than English? How could that be beneficial?
Is what I instantly thought. To get a grasp of why that is, we are going to need to delve into the wonderful world of tokenization.
The Token situation
To understand natural language, a model needs to decompose it into smaller chunks, called tokens.

Each token is then associated with a number, and the numbers are then stored into a vector, that can be processed by an algorithm.

The process is called tokenization and there are lots of different algorithms or tokenizers that can perform the task. Each tokenizer creates its own “dictionary” of tokens, each associated with a number. The “dictionary” depends on what they have been exposed to during training, which means that their performance can vastly differ between languages.
For example, the exact sentence used earlier, when translated to French, will not have the same number of tokens, as the tokenizer is using different tokens to decompose the sentence.

The data used
To make it a little bit easier to understand the different offerings, I have decided to compare them not only from a theoretical standpoint, but also from a practical one, by comparing prices for different models and in different languages.
To do so, I had to find a way to isolate as much variables as possible: I needed a dataset that would allow me to compare sentences with the exact same meaning across different languages.
This dataset exists and is made available by Amazon : it is called “MASSIVE” and has been used in multiple Data Science competitions since its release. It contains multiple sentences received by the Alexa assistant, across 50 languages, but we are only going to keep a few of them, chose arbitrarily because I thought they would be diverse enough to cover the potential differences :
- English
- Spanish
- Korean
- Hindi
- Chinese
All sentences in each language have been compacted into one long text, which has the exact same meaning for each language, containing lots of sentences, hopefully allowing us to evaluate the models’ performance and highlight pricing differences.
Without further ado, let’s analyse the results !
Language inequality
First thing we can try, knowing what we know about the billing differences, is to check wether the tokenizers used by OpenAI are biassed towards the English language, and if Google’s character approach fundamentally differs.
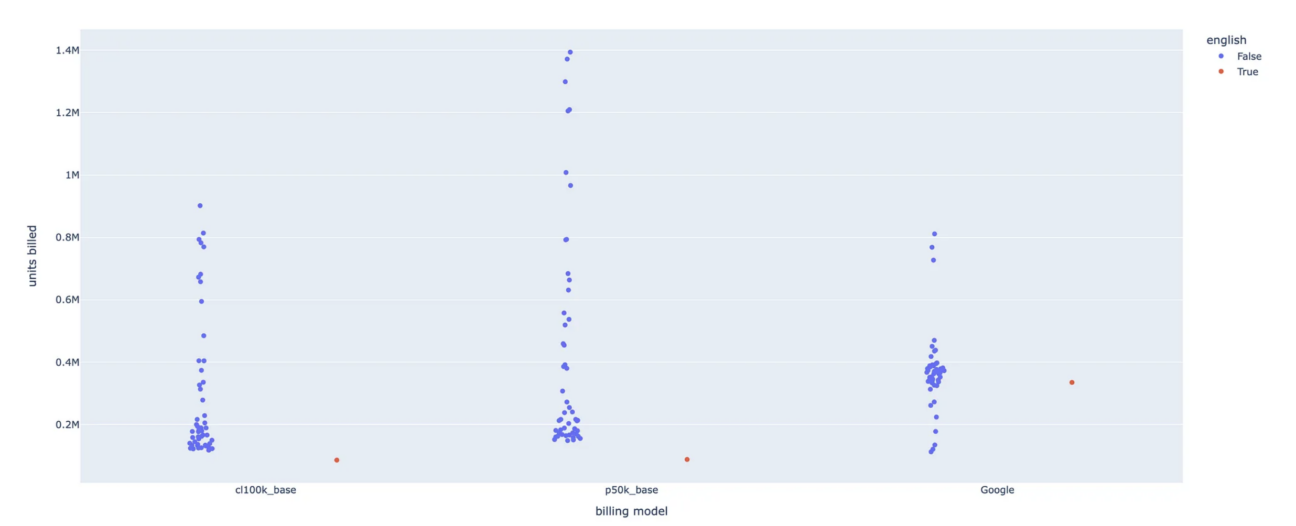
As we can see, OpenAI’s tokenizers (cl100k is the one used by ChatGPT and AdaV2 for embedding, while p50k is the one used by the Text models and the other embeddings models) exhibited a strong bias toward English, which was to be expected since most of the internet is in English, and the p50K tokenizer bills nearly 16 times more for Malayalam (one of the four languages spoken in South India) than for English.
The interesting thing to note is that english is the cheapest language for both of OpenAI’s tokenizers, while it sits in middle for Google’s character counter, meaning some languages might be better off using Google’s solution. However, it is essential to consider the overall pricing implications rather than solely focusing on tokenization biases.
Pricing differences
There is a last subtlety if we want the comparison to be as fair as possible, which is price. Due to the number of options and the differences in billing units, this little spreadsheet is not easy to understand without testing the prices on real data.

To make the comparison easier, these prices will be applied to our test data for different languages, and according to their respective billing units, so that we can compare the price for the exact same text across models and languages.
In order to stay as clear as possible, results have been divided into three categories: Embeddings, Text and Chat models.
Embeddings
Embeddings consist of text context-aware summarizations, mostly used in text analysis fields such as feelings analysis about a company on social medias, for example.

Google seems to be more expensive than OpenAI in the embeddings department, except for really dense languages, such as Korean.
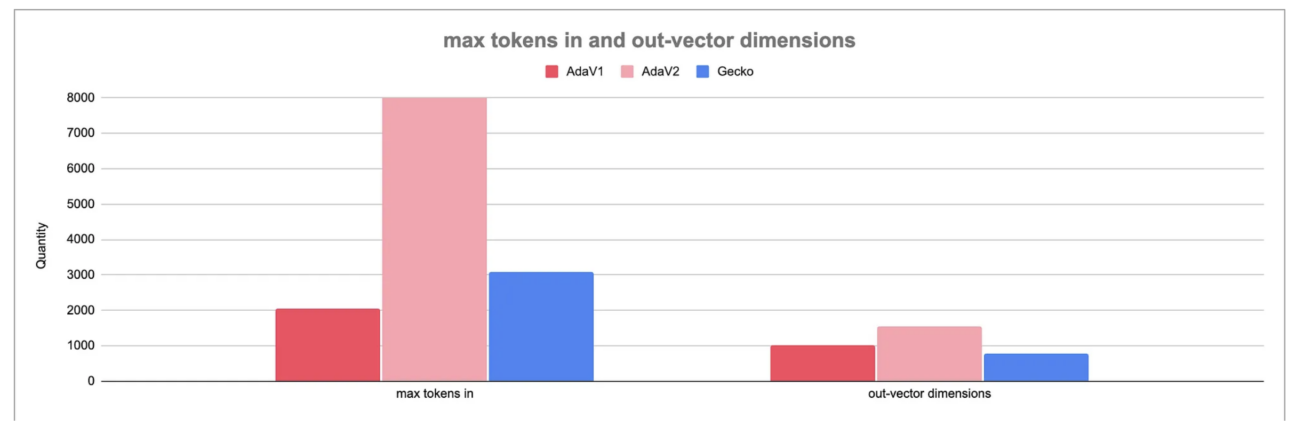
As it can be seen here, not only is AdaV2 cheaper to use to embed the same text, but it can also take in far more tokens (8191) than Google’s embeddings_Gecko (3072). It also returns a vector containing twice as much dimensions (1536 vs 768).
Officially, this kind of restrictions on Google’s side are due to their will to reduce latency as much as possible.
It should also be noted that, according to the company’s material, AdaV2 is both more efficient and less expensive than AdaV1, a statement that seems to be confirmed by our charts, at least according to the number of tokens and vectors the model can support.
Text
Here, the comparison becomes a little bit trickier, as OpenAI offers 4 different text-specialised models, from the all-powerful DaVinci down to the very light Ada.
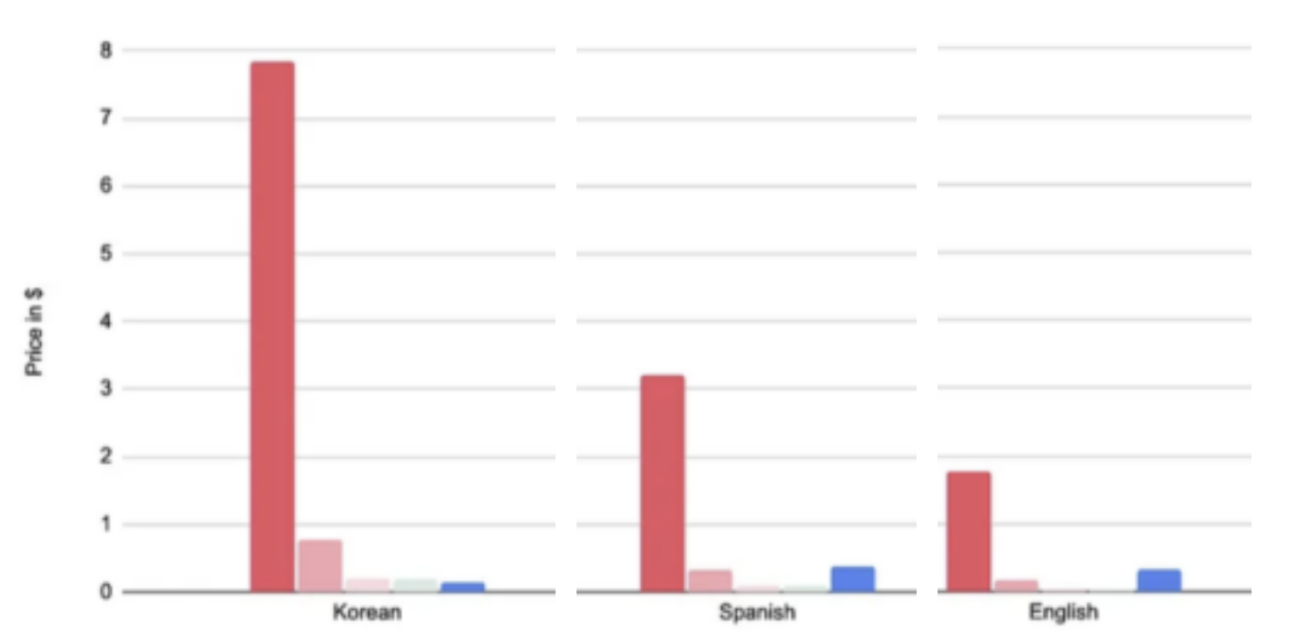
This first graph is not ideal to visualise, as DaVinci is far more expensive than the rest of the elements compared, so we take it out of the equation, as it seems to exist in a category of its own.

Price-wise, Text_Bison seems to be on-par with the Curie model from OpenAI. In the meantime Babbage and Ada don’t show that much of a difference in pricing for the text used here, which is to be expected, as their pricing only differs by 0.0001$ per thousand tokens. In order to really expose any significant difference in pricing, the text would need to be gargantuan.
But wait, there is a catch ! A quite significant one, that is. If we want to do an apple-to-apple comparison, based on similar levels of performance, we should, according to Google, compare Text_Bison to… DaVinci ! This model is indeed said to be the closest to Bison in its conception and performance. If this proves to be true, it would be a big win for Google when it comes to price / performance ratio.
Chat
In the realm of chat models, OpenAI offers 4 Chat-GPT variants as of writing, which can be seen in the sheet at the beginning of this article : GPT3.5 with 4K or 16K tokens context, and GPT4 with 8K or 32K tokens of context. The “context” is the number of previous tokens that d-the model can “remember” when generating a response.
Among these, the only logical comparison for Chat-Bison is GPT3.5 in its 4K context version, as they are said to be nearly equally capable, and can take into account a context composed of up to 4096 tokens.
The interesting part with Chat models is that OpenAI charges more for the answer tokens than for the input ones. It means that with the exact same text, let’s say a book, you will not pay the same if you want the model to generate it, or if you give it and ask to sum it up.
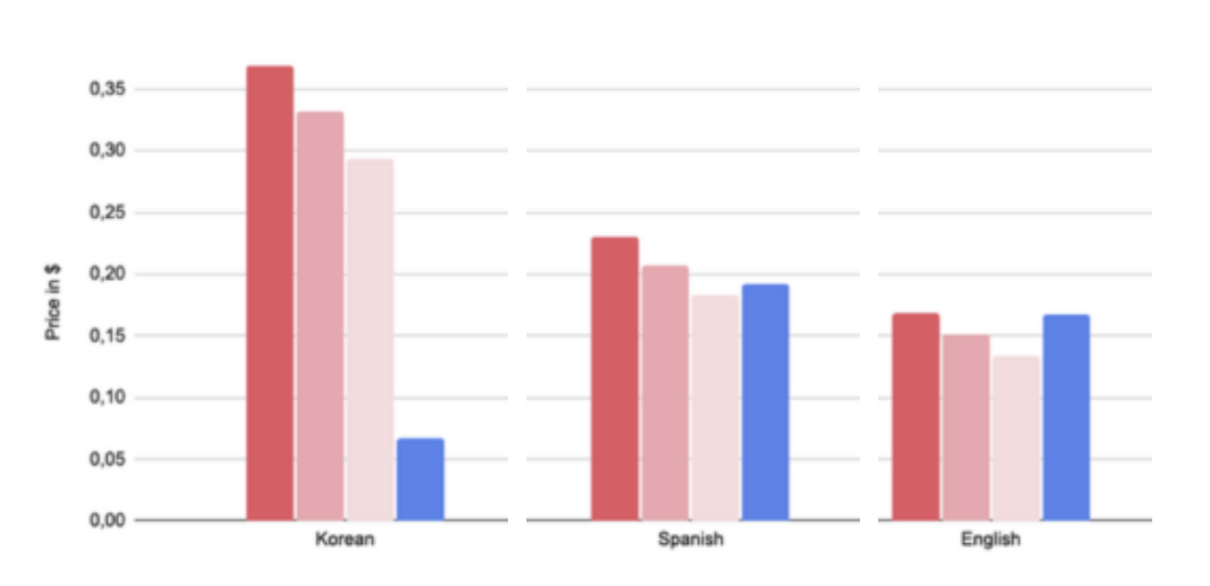
The 3 bars per language for GPT3.5 represent different proportion of in/out tokens (10% in / 90% out, 50 / 50, and 90% in / 10% out)
Some very interesting lessons of this Chat-models comparison are that :
- If you are working with Korean or Japanese text, Google is by far the cheaper option.
- In some languages, such as Spanish, French or German, the cheaper option will depend on your specific requirements : generating a significant amount of text with a relatively small prompt or summarizing large quantities of text.
Conclusion
In conclusion, the comparative analysis of generative AI pricing between OpenAI and Google Cloud provides valuable insights into their respective models. While Google’s character-based billing model seems to be a great deal for Korean speakers, OpenAI’s token-based approach appears to favor English speakers.
However, it is important to consider that pricing is not the sole factor in choosing between OpenAI and Google. Other considerations come into play, such as the power of the models offered.
At the time of writing, OpenAI has a competitive edge with its more powerful GPT4, which Google does not have any competitor to yet.
On the other hand, Google has already established a strong integration of generative AI within its Cloud Platform, which can be a significant selling point for certain companies.
Ultimately, when making a decision between OpenAI and Google, businesses should carefully evaluate their specific requirements, considering factors beyond pricing alone. The capabilities of the models, integration with existing infrastructure, and long-term strategic objectives should all be taken into account to make an informed choice in the rapidly evolving field of generative AI.

