This article was written by Guilherme Azevedo and Carlos Martins, both Team Lead & Senior Google Cloud Data Engineer at Devoteam Portugal
Prerequisites
- A Google account.
- BigQuery set up through Google Cloud (GCP).
- A configured dbt project.
What is Cloud Run?
Cloud Run is a fully managed Google Cloud tool that allows you to deploy containerized applications without managing infrastructure. It scales down to zero when not in use, ensuring cost savings as you only pay for resources when they are used. Cloud Run’s integration with Google Cloud services allows easy automation of workflows, such as job scheduling.
Architecture & Configuration
Before delving into Cloud Run, let’s explore the setup components:
- Dbt Project: Core of data transformation.
- Cloud Build: Automates building and deploying the containerized dbt project.
- Google Container Registry: Stores container images securely.
- Cloud Run: Executes the containerized dbt project serverlessly.

Step 1: Project Setup
- Create a service account in GCP with roles BigQuery Data Editor and BigQuery User
- Configure dbt profiles.yml as usual and then create a entrypoint.sh file in your dbt project root with:

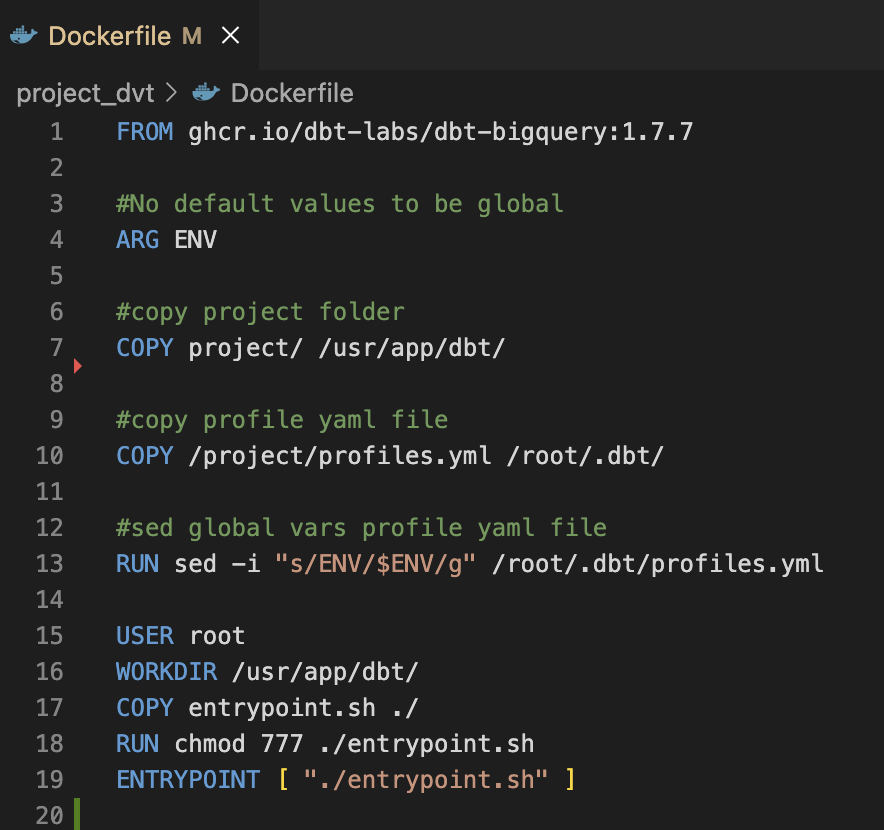
Step 2: Containerize dbtDockerfile
Create a Dockerfile to build image from it with the following content:
Cloud Build Configuration – Set up Cloud Build with:

Step 3: Create a Cloud Run Job
Unlike a Cloud Run service, which listens for and serves requests, a Cloud Run job only runs its tasks and exits when finished. A job does not listen for or serve requests.. To perform this setup you are required the following permissions:
- Cloud Run Developer (roles/run.developer)
- Service Account User (roles/iam.serviceAccountUser)
When creating a job, specify:
- Container image with the job code.
- Job name.
- Region.
- Number of tasks.

Set additional properties like memory, CPU, timeout configuration, retries, and parallelism.
To trigger the job (dbt run), you can do it manually or schedule it using Workflows and Cloud Scheduler.
Conclusion
Combining dbt with Cloud Run offers a scalable, cost-effective solution for on-demand data transformation. The main benefits are:
- Serverless Scalability: Automatic scaling based on demand.
- Cost-effectiveness: Pay only when Cloud Run processes requests.
To Be Continued …
Also read part two of this article, coming soon on this blog.

