✏️ Written by Jonas Ameye, Cloud Engineer at Devoteam G Cloud
This being my first Kubecon, I was amazed at the sheer size of this convention. People were bustling around filled with enthusiasm for technology. A showroom filled with amazing solutions, all bringing something unique to the table, could be found as a gathering ground in the middle of the convention. It was sometimes difficult to choose what talk to attend when there were several that piqued my interest happening at the same time. All of them taught important lessons or thinking points, but one of them intrigued me more than the others: The day we delete(d) production.

The talk that really caught my attention was a talk about the day a company deleted a third of their production environment. Initially, I was intrigued by how one goes about accidentally doing that, but eventually, it was a learning experience in how to properly handle such events.
The company in question has over three hundred clusters running their services. One day, while executing a maintenance script to clean up some orphaned clusters, they got messages from users about services being degraded. Quickly they aborted the maintenance script and were horrified to notice that over a hundred of their clusters were deleted. Due to a high level of redundancy, some good GitOps practices, and a little bit of luck, they had everything back up and running the same day.
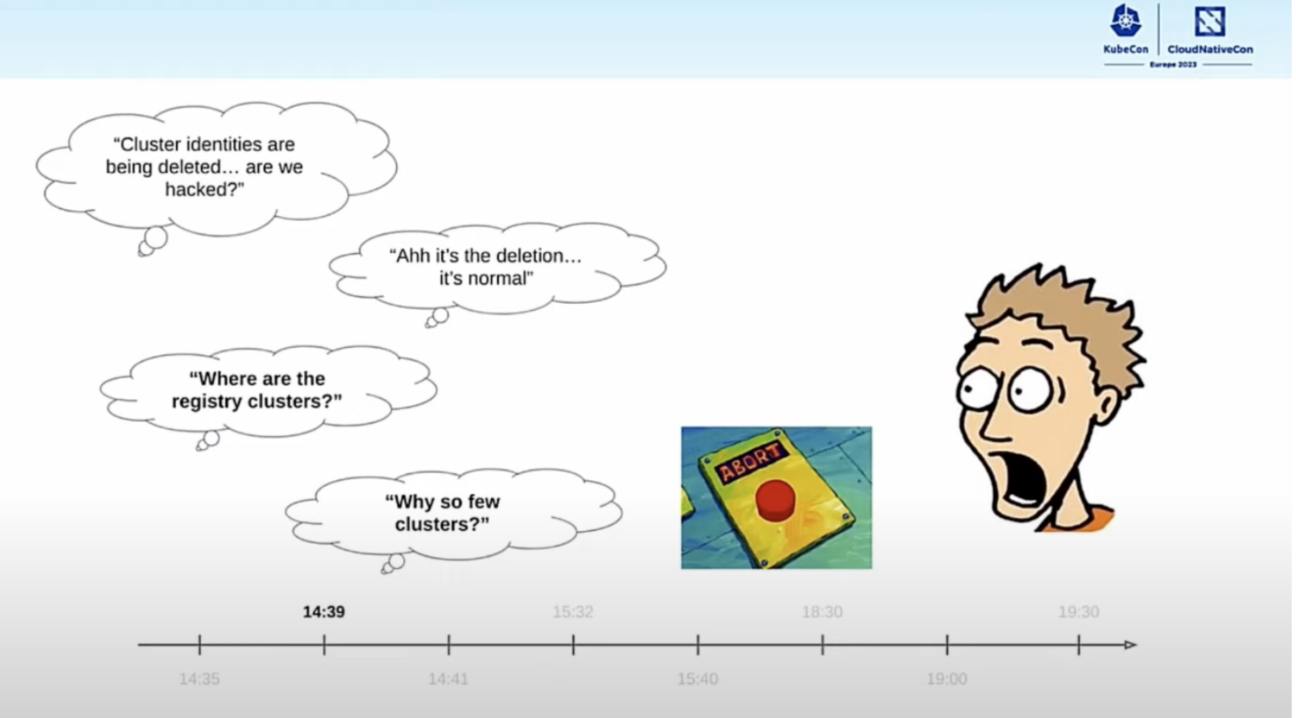
This story can teach us some important lessons
While of course, you want to prevent your production workload from being unintentionally deleted, it’s always good practice to have safeguards in place to reduce disruption when part of the production goes down, and have plans and resources in place to get everything back up and running as soon as possible.
Here are some key recommendations to achieve this, based on this talk and Devoteam’s own best practices:
- Build in redundancy. Don’t rely on one single point of failure for critical workloads you can’t afford to lose. High available setups with load distribution and failovers in place can make a loss of production workload unnoticeable for the consumers of your service.
- Limit hard dependencies. In a lot of modern setups, multiple services call on each other to execute tasks, process or fetch data, display images, etc. Sometimes, these tasks are not essential for the functioning of your application. While not having all services available in your application leads to a degraded experience, it is often still preferable over the application not working at all due to hard dependencies.
- Use Infrastructure as Code (IaC) or have other flows to quickly provision infrastructure. Using IaC can help you get your deleted workloads back up and configured exactly as before in a timespan that is negligible in contrast to having to spin up and configure everything back to how it was manually.
- Stay calm and communicate clearly. While losing part of production can be very stressful, it is important to keep organised and not act rashly. Communication is key to getting your team aligned and working on resolving the issue on time.
- Have backups. While fairly straightforward, it’s very important to have a good backup policy in place. No matter how extensive your infrastructure as code and your GitOps are, if all of your data is deleted and you have no backups anywhere, there is no way of getting that data back.

Take action and build a resilient infrastructure that can withstand these kind of mishaps.
Devoteam G Cloud can help you navigate through these challenges with their expertise in cloud engineering. Contact us today to get started and secure your business against unexpected disasters!

