This article was written by Paulo Jorge de Castro Pereira – Data Engineer Distributed Cloud @ Devoteam in Portugal.
While Cloud Workflows pricing is based on the number of steps executed, the advantages of a well-orchestrated pipeline far outweighs any minor cost increase.
Before starting
You should already have Cloud Workflows working properly in your Google Cloud (GCP) project.
User roles:
- Workflows Editor: This role allows you to create, edit, and deploy workflows.
- Workflows Invoker: This role allows you to execute (run) workflows.
- Logging Viewer: This role allows you to read and view logs.
Service account roles:
- Workflows Invoker
- Logging Log Writer
- Ensure your user has permission to act as the Service Account
To test the code, be sure to fulfil the above requirements.
Sample Cloud Workflow 1
We’ll begin by building two simple, dependent Cloud Workflows. Create a new workflow, choose a low-carbon region, and select the service account for launching. (No need to configure environment variables, labels, or triggers for this example).
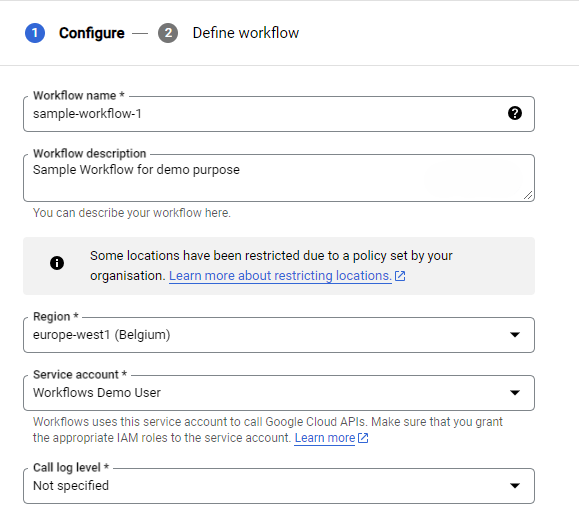
The pre-built workflow includes functional code, which we’ll slightly modify. Copy and paste the following code:
main:
steps:
- init:
assign:
- searchTerm: "europe"
- readWikipedia:
call: http.get
args:
url: '<https://en.wikipedia.org/w/api.php>'
query:
action: opensearch
search: '${searchTerm}'
result: wikiResult
- returnOutput:
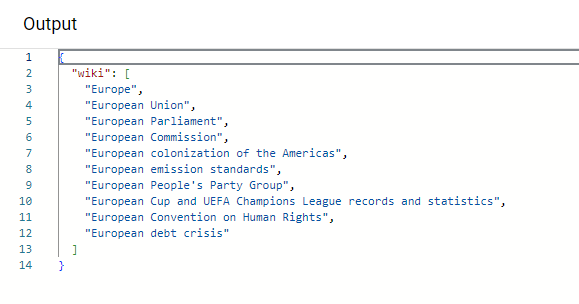
return: {"wiki":'${wikiResult.body[1]}'}This workflow searches Wikipedia for articles related to “europe.” Deploy the workflow without changes, and you should see similar results.
Sample Cloud Workflow 2
Next, we’ll create a second workflow that relies on the output of the first. This workflow will convert a list of strings to uppercase, demonstrating a simple dependency (more complex scenarios are possible, but not the focus here).
Follow the same creation process as the first workflow to get started.
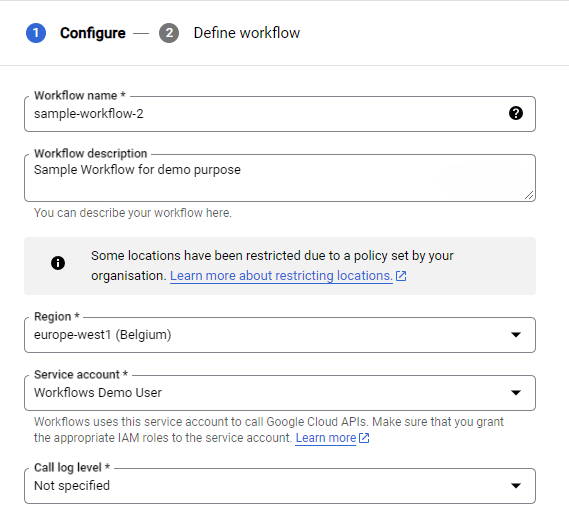
Replace the default code with this one:
main:
params: [wikiResults]
steps:
- initializeUppercaseResults:
assign:
- uppercaseResults: []
- convertToUppercase:
for:
value: wikiItem
in: ${wikiResults.wiki}
steps:
- appendToUppercaseResults:
assign:
- uppercaseResults: ${list.concat(uppercaseResults, text.to_upper(wikiItem))}
- returnOutput:
return: ${uppercaseResults}
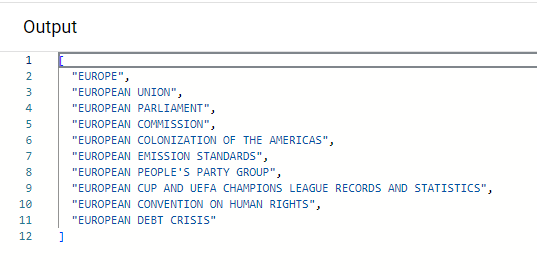
This code converts a list of strings to uppercase. Deploy the workflow and try running it without any input. It will fail due to the empty default dictionary. However, it should work with the following input:
{
"wiki": [
"Europe",
"European Union",
"European Parliament",
"European Commission",
"European colonization of the Americas",
"European emission standards",
"European People's Party Group",
"European Cup and UEFA Champions League records and statistics",
"European Convention on Human Rights",
"European debt crisis"
]
}The result should be the following:
Orchestrator Workflow
With both workflows deployed and tested, we can now create an Orchestrator Workflow to automatically trigger Workflow 2 upon the successful completion of Workflow 1. For this, we’ll need the ID and location of both workflows.
Create a new workflow named “orchestrator-workflow” (description is optional). Choose a low-carbon region and the same service account used for the previous workflows.
In this example, since we need to pass output from Workflow 1 to Workflow 2, the code is slightly more complex than a simple for loop. However, a simplified orchestrator workflow code is provided at the end of this post for scenarios where value sharing isn’t required.
Add the following code:
main:
params: [args]
steps:
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- firstWorkflowId: "sample-workflow-1"
- secondWorkflowId: "sample-workflow-2"
- location: "europe-west1"
- launch_first_workflow_execution:
call: http.post
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/projects/"+project_id+"/locations/"+location+"/workflows/"+firstWorkflowId+"/executions>"}'
result: firstWorkflowResult
- set_first_execution_id:
assign:
- execution_id: ${firstWorkflowResult.body.name}
- exponential_backoff_retries_for_first_workflow:
try:
steps:
- get_first_execution_state:
call: http.get
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/>"+execution_id}'
result: firstWorkflowState
- set_first_execution_state:
assign:
- execution_state: ${firstWorkflowState.body.state}
- log_state_first_workflow:
call: sys.log
args:
text: '${firstWorkflowId +" state: "+ execution_state}'
severity: INFO
- induce_backoff_retry_if_first_state_not_done:
switch:
- condition: ${execution_state != "SUCCEEDED"}
raise: ${execution_state}
retry:
predicate: ${execution_state_predicate}
max_retries: 2
backoff:
initial_delay: 4
max_delay: 45
multiplier: 2
- get_first_workflow_output:
call: http.get
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/>"+execution_id}'
result: firstWorkflowOutput
- log_first_output:
call: sys.log
args:
text: '${firstWorkflowOutput.body.result}'
severity: INFO
- launch_second_workflow_execution:
call: http.post
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/projects/"+project_id+"/locations/"+location+"/workflows/"+secondWorkflowId+"/executions>"}'
body:
argument: '${firstWorkflowOutput.body.result}'
result: secondWorkflowResult
- set_second_execution_id:
assign:
- execution_id: ${secondWorkflowResult.body.name}
- exponential_backoff_retries_for_second_workflow:
try:
steps:
- get_second_execution_state:
call: http.get
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/>"+execution_id}'
result: secondWorkflowState
- set_second_execution_state:
assign:
- execution_state: ${secondWorkflowState.body.state}
- log_state_second_workflow:
call: sys.log
args:
text: '${secondWorkflowId +" state: "+ execution_state}'
severity: INFO
- induce_backoff_retry_if_second_state_not_done:
switch:
- condition: ${execution_state != "SUCCEEDED"}
raise: ${execution_state}
retry:
predicate: ${execution_state_predicate}
max_retries: 2
backoff:
initial_delay: 4
max_delay: 45
multiplier: 2
- get_second_workflow_output:
call: http.get
args:
auth:
type: OAuth2
url: '${"<https://workflowexecutions.googleapis.com/v1/>"+execution_id}'
result: secondWorkflowOutput
- log_second_output:
call: sys.log
args:
text: '${secondWorkflowOutput.body.result}'
severity: INFO
- returnSuccess:
return: "All pipelines finished with success! Check logs for more details."
execution_state_predicate: # Subworkflow to check if execution is complete
params: [execution_state]
steps:
- init:
assign:
- failureStates: ["FAILED","CANCELLED"]
- condition_to_retry:
switch:
- condition: ${execution_state in failureStates}
return: False # Stop Workflow
- condition: ${execution_state != "SUCCEEDED"}
return: True # Continue waiting
- otherwise:
return: False # Stop WorkflowYou should see a result similar to the following:

Opening the logs tab we can see the array of strings transformed.

The process is simple:
- define variables,
- launch the first workflow,
- then monitor its state with exponential backoff retries.
This is quick for simple workflows, but complex ones (e.g., >1-2 minutes) may need longer retry times (e.g., 4-5 minutes). This highlights dependency handling, where the second workflow relies on the first’s output.
Cloud Workflows simplify building smart pipelines, excelling at managing dependencies for complex orchestrations.
Bonus: Simplified Orchestrator
Here’s a simpler orchestrator workflow for cases where variable sharing isn’t needed, only dependency tracking.
main:
params: [args]
steps:
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- workflowIds: ["sample-workflow-1", "sample-workflow-2"]
- location: "europe-west1"
- failureStates: ["FAILED","CANCELLED"]
- executeWorkflows:
for:
value: workflowId
in: ${workflowIds}
steps:
- launchWorkflow:
call: http.post
args:
auth:
type: OAuth2
url: ${"<https://workflowexecutions.googleapis.com/v1/projects/>" + project_id + "/locations/" + location + "/workflows/" + workflowId + "/executions"}
result: executionResult
- trackExecution:
assign:
- execution_id: ${executionResult.body.name}
- waitForCompletion:
try:
steps:
- getExecutionState:
call: http.get
args:
auth:
type: OAuth2
url: ${"<https://workflowexecutions.googleapis.com/v1/>" + execution_id}
result: executionState
- set_second_execution_state:
assign:
- execution_state: ${executionState.body.state}
- logState:
call: sys.log
args:
text: ${workflowId + " state -> " + execution_state}
severity: INFO
- checkCompletion:
switch:
- condition: ${execution_state != "SUCCEEDED"}
raise: ${execution_state} # Retry if not in a failure state and not yet succeeded.
retry:
predicate: ${execution_state_predicate}
max_retries: 2
backoff:
initial_delay: 4
max_delay: 45
multiplier: 2
- returnSuccess:
return: "All pipelines finished with success! Check logs for more details."
execution_state_predicate: # Subworkflow to check if execution is complete
params: [execution_state]
steps:
- init:
assign:
- failureStates: ["FAILED","CANCELLED"]
- condition_to_retry:
switch:
- condition: ${execution_state in failureStates}
return: False # Stop Workflow
- condition: ${execution_state != "SUCCEEDED"}
return: True # Continue waiting
- otherwise:
return: False # Stop WorkflowThis structure is similar to the previous example but uses a for loop to easily add more workflows to the workflows list. Feel free to experiment, but note that this simplified orchestrator isn’t compatible with the previous workflows due to their dependency on output-as-input, a feature not included here.
Conclusion: Simplify Cloud Workflows
This blog post outlines strategies for simplified orchestration of Cloud Workflows. Using Google Cloud APIs, you can create robust pipelines to manage complex workflows.
The code samples provided serve as a starting point for your own projects. Remember, splitting workloads into multiple workflows optimises cost and enhances flexibility.
Though the orchestrator adds steps, the benefits of a smarter pipeline outweigh the minor increase in execution time.
Don’t miss our guide on How to set up a Cloud Run job to read and write on BigQuery.

