Why a data lake?
This is of course just one example. Think about what you could do in your company if you have all your information in one place! As some of you may have heard by now, around 80% of all data comes in unstructured form. As you can guess, a lot of useful information can be hidden in this data.
Why did we not do this before? Well, unstructured data is exactly what it sounds like. Not well structured. This means that it has always been hard to analyse. Plain text information used to have to go through manual analysis before any useful information could be gained. This was both time consuming and expensive.
However, now there are many machine learning techniques that can analyse plain text as well as images, videos etc. This means that extracting the information can be automated. Incorporating this extra information can heavily impact the efficiency of your organisation and can improve customer experience.
How to build your own data lake?
Now that we are clear on the different terms and we know what we can gain, let’s talk about how you can get a data lake on Google Cloud Platform (GCP). As you can see in the diagram below, the ideal service to start your data lake is Google Cloud Storage.
Cloud Storage offers unlimited object storage for files of up to 5TB a piece. It has different storage classes, so you can store your rarely accessed information cheaper and it has good SLAs with regards to durability and availability. Cloud Storage integrates nicely with all other GCP services , so you can leverage them from the moment your data arrives.
In case you are not ready to make the full switch to cloud native, GCP can even be used to replace your HDFS (in fact both are based on a white paper from Google on GFS). This means that your applications will not have to be drastically changed to work with your data lake on Cloud Storage.
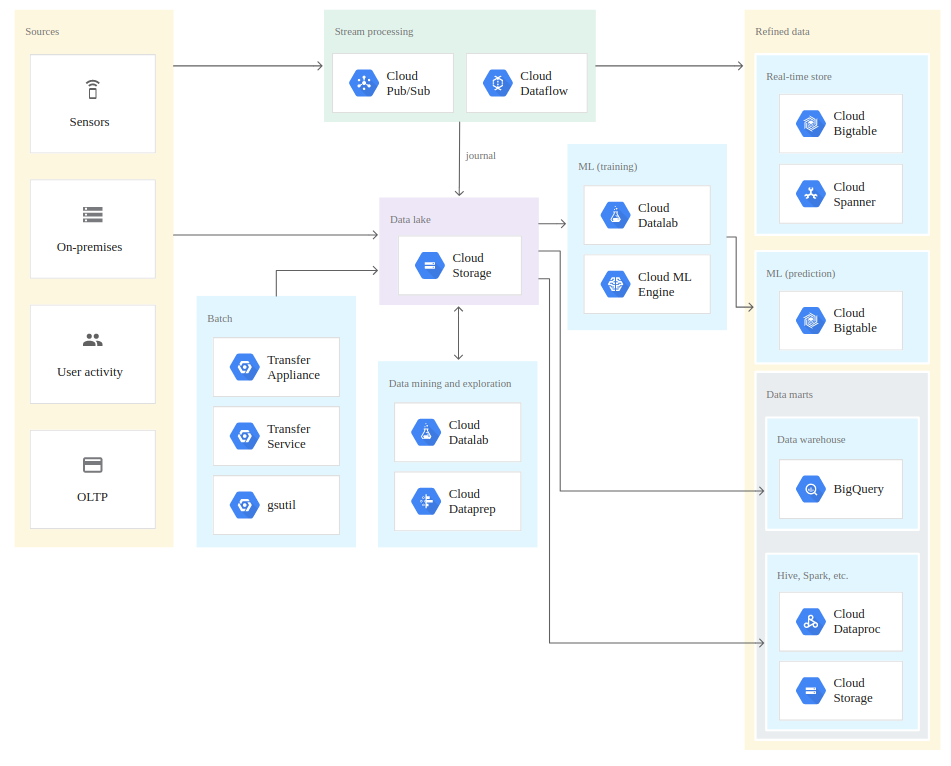
So what are the main steps to get the benefits of a data lake, as explained above?
- Gather all of your raw data in Cloud Storage. Use tools like the messaging service Cloud Pub/Sub or beam pipelines in Cloud Dataflow to extract, transform and load (ETL) data from Cloud Storage to a different serving layer (or back to Cloud Storage).
- Leverage the fact that you can access all the information of your company in one place and think creatively about what you can do with your unstructured data. Leverage this data in your serving layers. An example for such a serving layer could be a data mart.
- Present the data in the data mart to its end users and allow them to gain better insights with tools like Data Studio and Looker. Use this to improve your customer experience, gain profit and make your organisation more efficient.

A concrete data lake use case example on Google Cloud Platform
Let’s get into a more concrete example for a fictional business called Rainforest. Rainforest has an online store with a lot of products. They have a large amount of concurrent users from all over the globe. To ensure that they do not sell more than they have in stock, they use a global transactional SQL based database (like Cloud Spanner).
Users that have bought an item, can leave a review in the form of a score and plain text commentary. Right now, Rainforest has a table in their data warehouse (let’s say in BigQuery) that has all their products and associated scores. They are not using the text associated with that score.
Rainforest has noticed that users do not always give a score that correlates to their comment. For example a user might say: “Best product I’ve ever bought” and still only rate the product one star out of five.
Besides that, some customers also send text feedback via mail. Because of this, Rainforest has decided to level up their game. They want to start a test project for a data lake, so they dump all their review data (comments and emails) in Cloud Storage. They use a Dataflow pipeline to extract the text and call the Natural Language API provided by Google to get the sentiment for the review. They then add this sentiment together with the other information about the purchase into their data warehouse in BigQuery.
Rainforest no longer needs to rely solely on the amount of stars a product has received to make a recommendation, but they can use the sentiment of a review to create a new score that will be used by their recommendation engine. This gives them an edge over their competitors and drives their business forward.
This was just a small example of what you can do with a data lake. Of course, the exact implementation will vary from use case to use case, but the principle remains the same. Store all of your information in one place in its raw form, combine it in useful ways and use these to improve your business. Your company probably has a lot of data that it isn’t leveraging right now, so I hope this blog has inspired you to start thinking about what you can do with your data and drive your business forward!

Ready for the next step? Discover where to build your Datalake using Google Cloud
Comparing the strengths and weaknesses of Google Cloud solutions like Cloud Storage, BigQuery, and Cloud SQL to build a data lake that suits your company’s needs.

