If you have been keeping up with everything about data, then you will surely have heard terms like ‘data lake’, ‘data warehouse’, ‘data mart’, etc. But what exactly is the difference between them? Well, there is some discussion around this topic, so I will share what Google has to say about this.
What is a data warehouse?
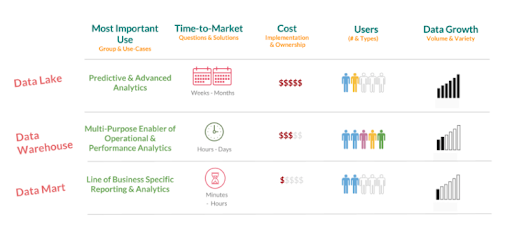
A data warehouse is a collection of all of the structured data that a company has in one place. Why is this useful? Having all your data in one place means that it is easy to combine.
Data is no longer in separate silos and the time to insight (TTI) is decreased. The goal is not only to have all your data in one place, but also to have a clear view of the lineage of your data.
This way you know exactly where your data comes from and you can validate the results from an analysis by verifying that the data is correct.
What is a data mart?
A data mart is a subset of a data warehouse. The goal is to have all the information related to one subject in one place. This makes it easy for end users to use the data and allows them to work on a small subset, thereby limiting the resources used.
Additionally, this enhances security as you’re exposing as little information as needed for each specific use case.
What is a data lake?
The benefits of having a data warehouse and data marts are clear. So why do you need a data lake? What is a data lake, even?
Well, a data lake is similar to a data warehouse, but it is broader. The two can (and should) be used alongside each other.
A data lake includes all unstructured information like reports, pictures, text files and any information you can store. This includes the structured data that you would normally put directly into your data warehouse. The idea is that data might not seem useful now, but it might well be in a few months. Storage in the Cloud is cheap, so why would you want to miss that opportunity?
Important to note is that data in your data lake should be raw and unprocessed. The refinement is done when presenting to the different serving layers (like a data warehouse) that your business has. While some of the serving layers might change over time, the existing information in the data lake remains untouched. The main idea is to add rather than overwrite or change.
With all this data you can do a lot of things. For example, instead of importing your structured data directly in your data warehouse, you now first store it in your data lake, then enrich it with the information you can gain from the unstructured data and put that in your data warehouse.

Ready for the next step? Discover where to build your Datalake using Google Cloud
Comparing the strengths and weaknesses of Google Cloud solutions like Cloud Storage, BigQuery, and Cloud SQL to build a data lake that suits your company’s needs.

