Recently I had the pleasure and opportunity to work with Google Cloud Data Fusion and experiment with it myself. In my experience it is always best to get your hands dirty, try and experiment with new tools. Cloud Data Fusion is powered by the OSS project CDAP, Cask Data Application Platform, and offered as a beta service on Google Cloud Platform. It’s basically developer-centric middleware for developing and running Big Data applications. In this blog post, that consists out of 2 parts, I’ll tell you about my experience with creating a data warehouse with Google Cloud Data Fusion. Here we go for part 1.
In God we trust, all others bring data.” — W. Edwards Deming
So what is Google Cloud Data Fusion? It’s a fully managed, cloud native data integration service that helps users efficiently build and manage ETL/ELT data pipelines. It enables users to create scalable production data pipelines using a graphical interface, and with a variety of pre-configured connectors and different options for transformations. This enables organisations to focus more on the insights and less on the infrastructure.
If you want to learn more on what Cloud Data Fusion is, please read our previous blog post. In what follows, I’ll focus on providing practical information and my own experience with Cloud Data Fusion.
For what exactly can you use Google Cloud Data Fusion?
To give you an idea of one possible application of Cloud Data Fusion: the purpose of the project I have recently worked on was to create a data warehouse in BigQuery. For the POC for our customer, we used Cloud Data Fusion to read data tables from an on-premises Oracle Data Warehouse. We then ingested them into BigQuery and performed data manipulations to clean and denormalise the tables.
Finally, we saved these into new BigQuery tables which will serve as the source data for business dashboards.
Visual Pipelines
This project aimed to automate incremental loads and visualise the data in Google Data Studio dashboards. The customer had a key requirement to have a platform which will enable them to visually create data pipelines.
This means that, instead of writing a lot of Spark or MapReduce jobs themselves, they wanted to create pipelines by just dragging and dropping. Or at least to get as close to this way of working as technically possible.
This is where Cloud Data Fusion shines, as you can create data pipelines just in a couple of clicks.
Persistent staging area
Data Vault modeling is used in the customer’s current data warehouse design to keep all the history and to create Data Marts (source tables for dashboards) to changing business requirements.
Our customer keeps all the historic changes in journal tables. Every change is recorded with a date and change id, and appended to a related journal table of the main table. We decided to design a persistent staging area to replicate prepared staging tables coming from their Oracle Data Warehouse.
The persistent staging area is the inbound storage area for data from the source systems. With incremental loads – by appending and not deleting historical data and changes – specified on table level, this enables keeping all the historical snapshots of data so that they can analyse the different states of data historically.
To accomplish the project goals, four steps were involved:
- Initial Load: Batch load the tables
- Incremental Load: Upload the tables by checking the changes (Updates, Deletes, Inserts)
- Persistent Staging: Storing the updated tables in the persistent staging area
- Data Marts: Creating Data Marts and visualising the data on visually attractive dashboards in Google Data Studio
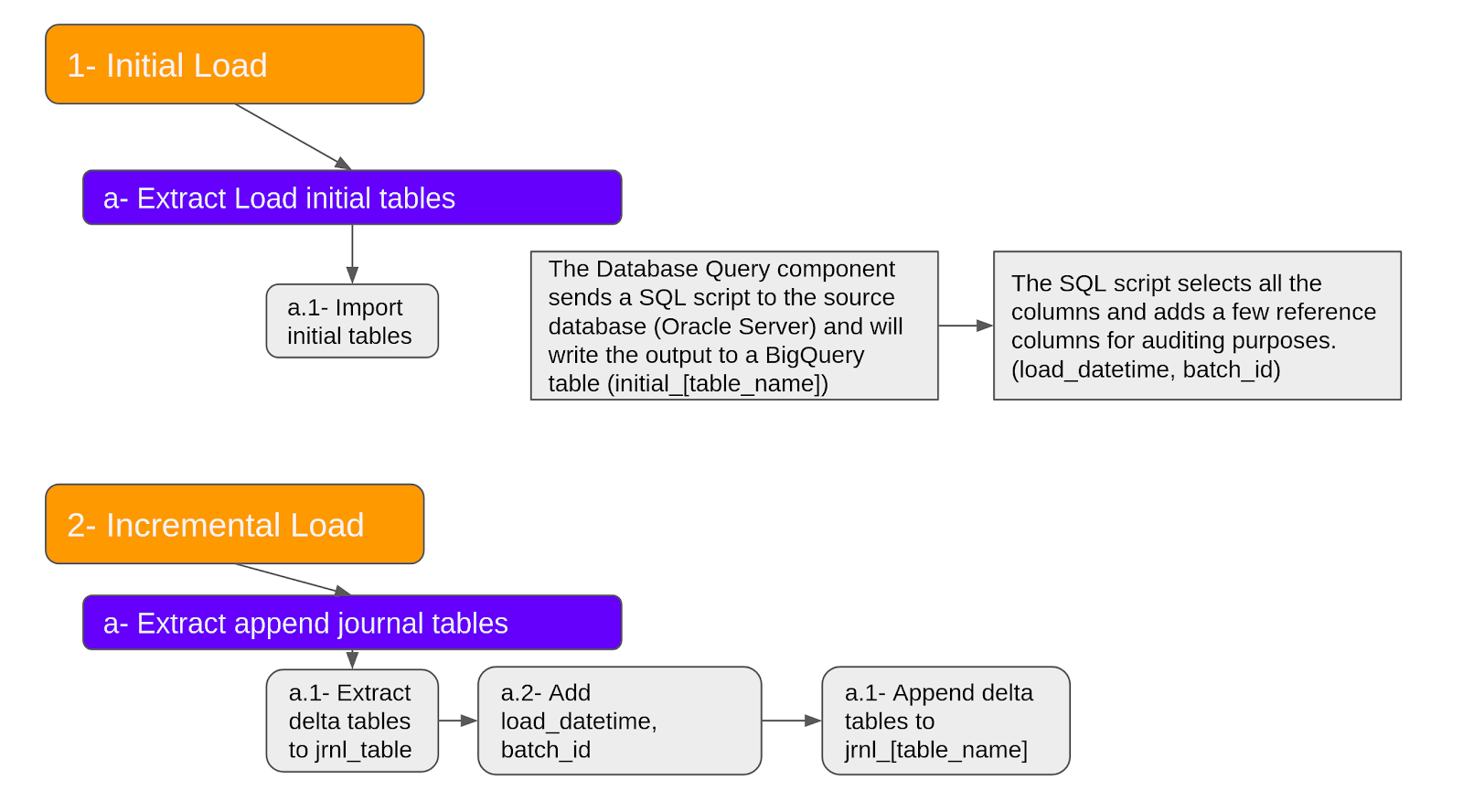 Initial and Incremental Load Pipelines
Initial and Incremental Load Pipelines
Load times & Batch id
Initially all the tables are ingested into BigQuery in batch. In order to keep track of the load times and batches for uploads, two additional columns are created: load_time and batch_id. For the incremental load pipeline, all journal tables are extracted and ingested into BigQuery. This pipeline is scheduled to run daily and to append to the journal tables.
The persistent staging area is designed to have two tables:
- Full data table (staging table)
- Current data table
In the full data table, all the data is kept so the customer can roll back in time and see the full data for previous dates. The current data table holds the current up to date full data so it can be used to create denormalised source tables for dashboards, or to enable quick analysis.
Connector plugins
The great thing about Cloud Data Fusion is that, in addition to internal connectors such as Cloud Spanner, Cloud Datastore, Cloud Storage etc…, the service enables you to install external connector plugins such as the Oracle Database Connecter Plugin.
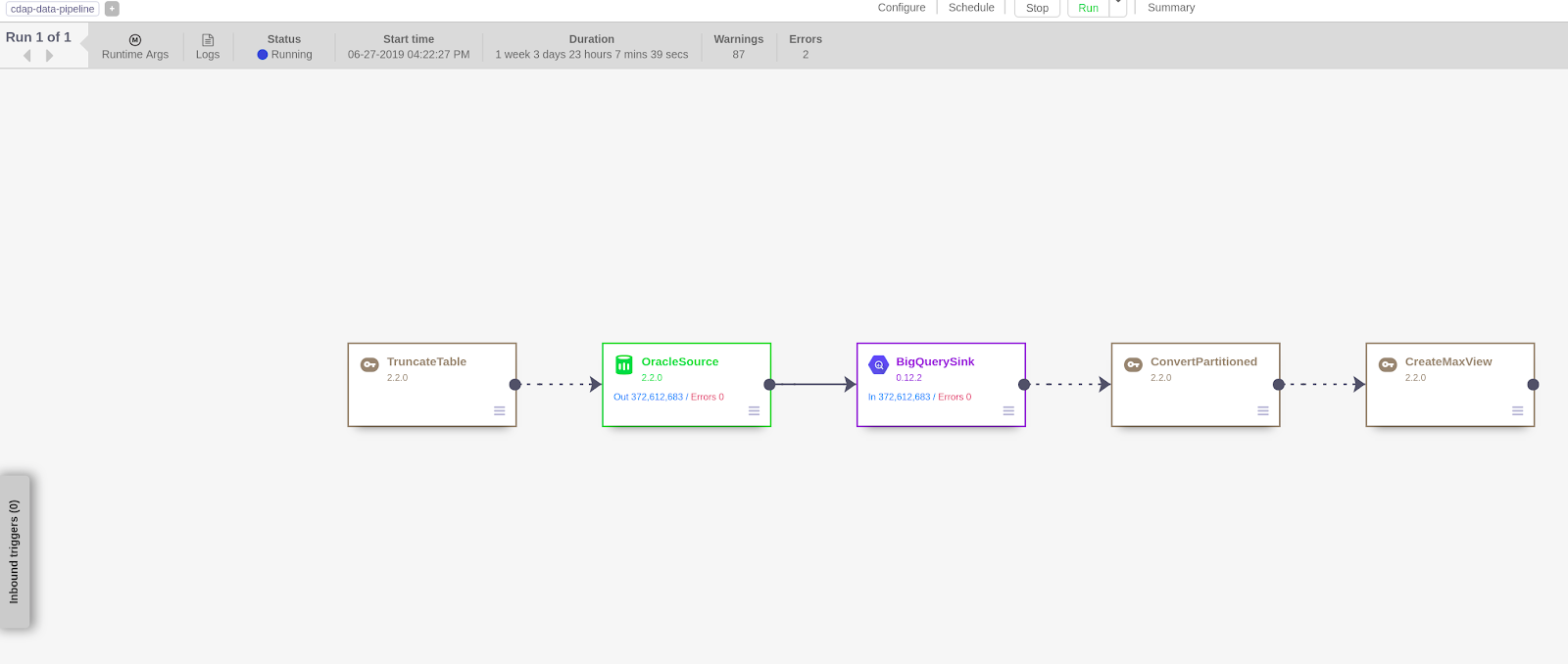
Using the Oracle Database Connecter Plugin, we were able to create the pipelines to extract and ingest data into BigQuery easily.
Connecting to Oracle Database and Ingesting data Into BigQuery is easy with Google Cloud Data Fusion”
You just drag and drop and put in your credentials and parameters for connecting to a database. You can even run bash scripts, or basically any code you want that is using Virtual Machines, by using “Remote Program Executor Properties”. This way you can have as much automation as you want, while keeping more programmatically control on some processes. You can also schedule individual jobs from inside Cloud Data Fusion to run in regular intervals.
We’re entering a new world in which data may be more important than software.” – Tim O’Reilly, founder at O’Reilly Media.
Cloud Dataproc as the Execution Environment
Behind the scenes, Cloud Data Fusion uses Dataproc as an execution environment. Cloud Data Fusion creates ephemeral execution environments, which provisions Dataproc cluster(s), to run pipelines when you manually run your pipelines or when pipelines run through a time schedule or a pipeline state trigger. Since it is a managed service, you don’t have to deal with a lot of configurations for resources and installations for the initialisation.
So if you have Hadoop or Spark pipelines already, Dataproc is a good choice for your data pipelines.
At the moment you can choose to run pipelines as MapReduce, Spark, or Spark Streaming programs for big data processing in Google Cloud Data Fusion. But maybe in the near future we will be able to run pipelines using Google Cloud Dataflow as well! Cloud Dataflow is a service on Google Cloud Platform that enables users to run Apache Beam based jobs for either batch or streaming pipelines.
Why choose Cloud Dataflow over Cloud Dataproc?
With Cloud Dataflow, you can focus only on only logic and computation, not on the provisioning of your clusters. It allows you to create a template for your Dataflow jobs to simplify recurrent tasks, when you only need to change some parameters. Cloud Dataflow gives you automatic scalability, which means you can scale down or up based on the process automatically instead of having a predetermined cluster preference.
You’re also able to operate your pipelines between SDKs and different runners such as Dataflow Runner, Apache Spark or Apache Flink.
In general, you should choose Cloud Dataflow over Cloud Dataproc if…
- you don’t have dependencies on specific tools or packages in Apache Hadoop ecosystem (such as Apache Pig, Hive or Spark)
- you don’t have an existing Hadoop cluster that needs migrating to GCP
- you require hands-off serverless DevOps approach to operations
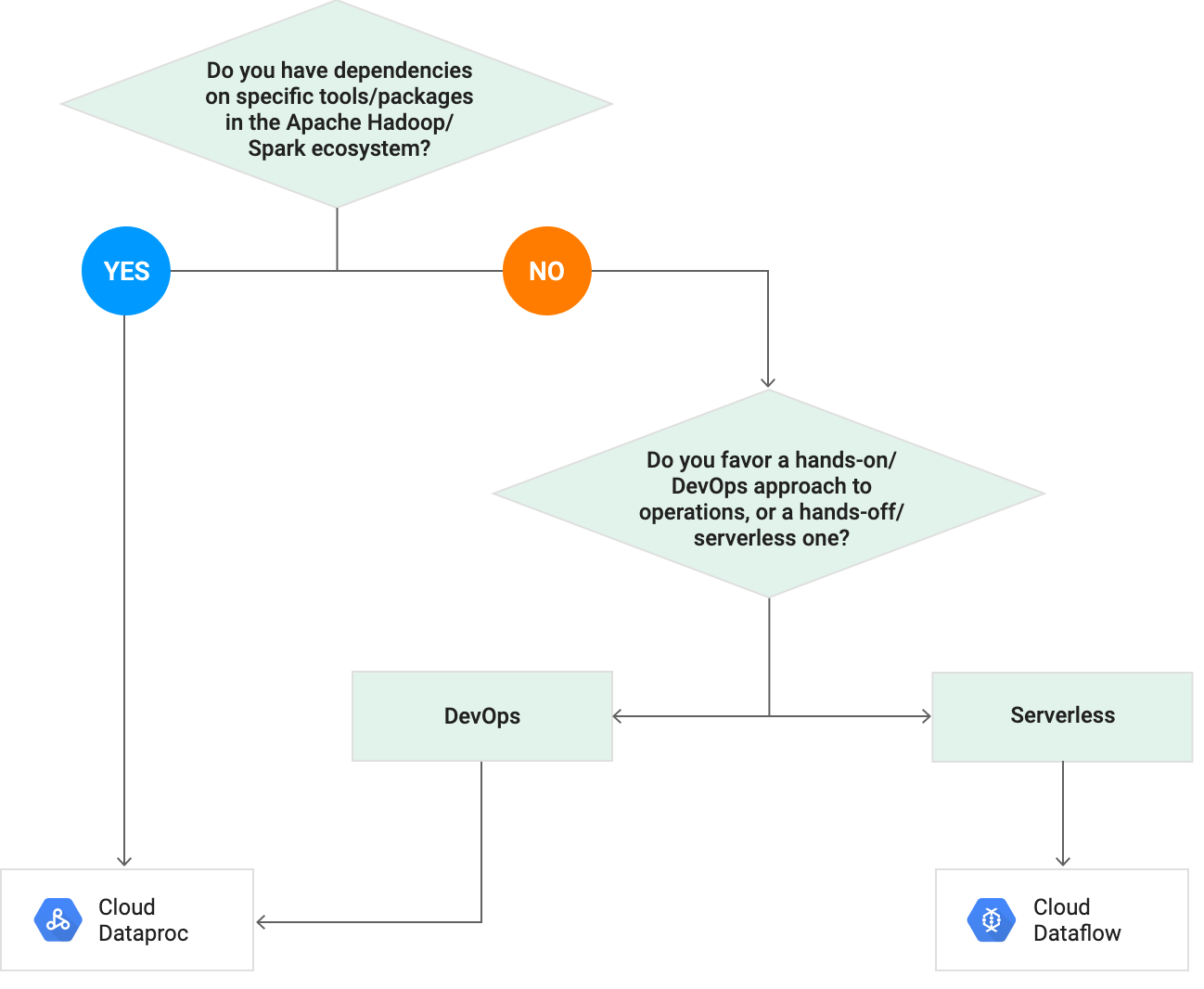 Cloud Dataflow vs. Cloud Dataproc: Which one to use? Source
Cloud Dataflow vs. Cloud Dataproc: Which one to use? Source
In summary, either Dataflow or Dataproc are very powerful technologies that can be used for processing massive data sets. Depending on the use case one can be more advantageous than the other. But in my opinion it would be good to have both options in Cloud Data Fusion.
This was part 1. In part 2 I, explain how we created and scheduled the data pipeline with Google Cloud Data Fusion, plus how we wrangled the data. I also share the pros and cons of using Cloud Data Fusion. Read it here!

