In part 1 of this post I explored for what you can use Google Cloud Data Fusion exactly, explaining the use case of a POC for one of our customers. I also talked about the differences between Cloud Dataflow and Cloud Dataproc. The next step in creating a data warehouse with Google Cloud Data Fusion is to create the data pipeline, wrangle the data, and to schedule and export the pipeline. Read on to see how I did this, plus my final thoughts on the pros and cons of using Google Cloud Data Fusion.
Creating the Pipeline
Creating a data pipeline is quite easy in Google Cloud Data Fusion through the use of Data Pipeline Studio. In there you select your data source, select the transformation that you want to perform, and define the sink.
These are done with just a couple of clicks and drag and drop actions.
Once you click on ‘Create Pipeline’ you end up in the Pipeline Studio. You then have 6 options:
- Source
- Transform
- Analytics
- Sink
- Conditions and Actions
- Error Handlers and Alerts
You can select amongst various types of data source connectors to connect your data, such as:
- BigQuery
- Cloud Data Store
- Cloud Storage
- Cloud Spanner
- Microsoft Excel
- FTP
- Amazon S3
- Etc…
Once you select the data source, Data Pipeline Studio creates a box for you on the grid. At this point you need to put the configuration parameters by clicking on to “properties”.
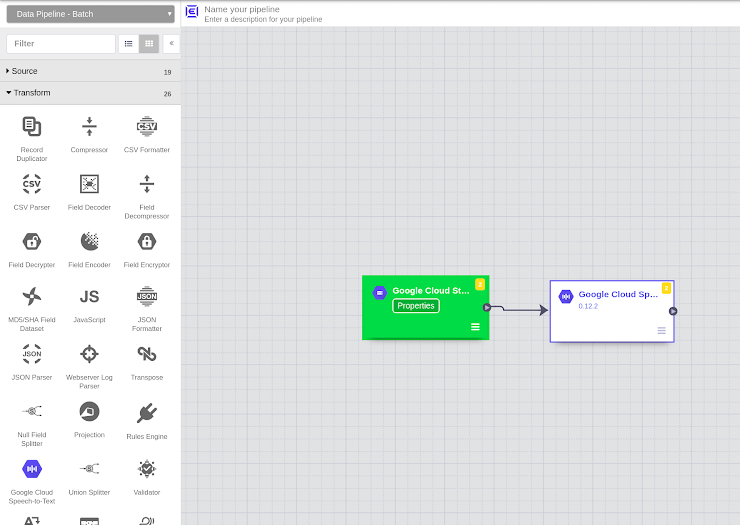 Pipeline Studio and adjusting properties of the data sources
Pipeline Studio and adjusting properties of the data sources
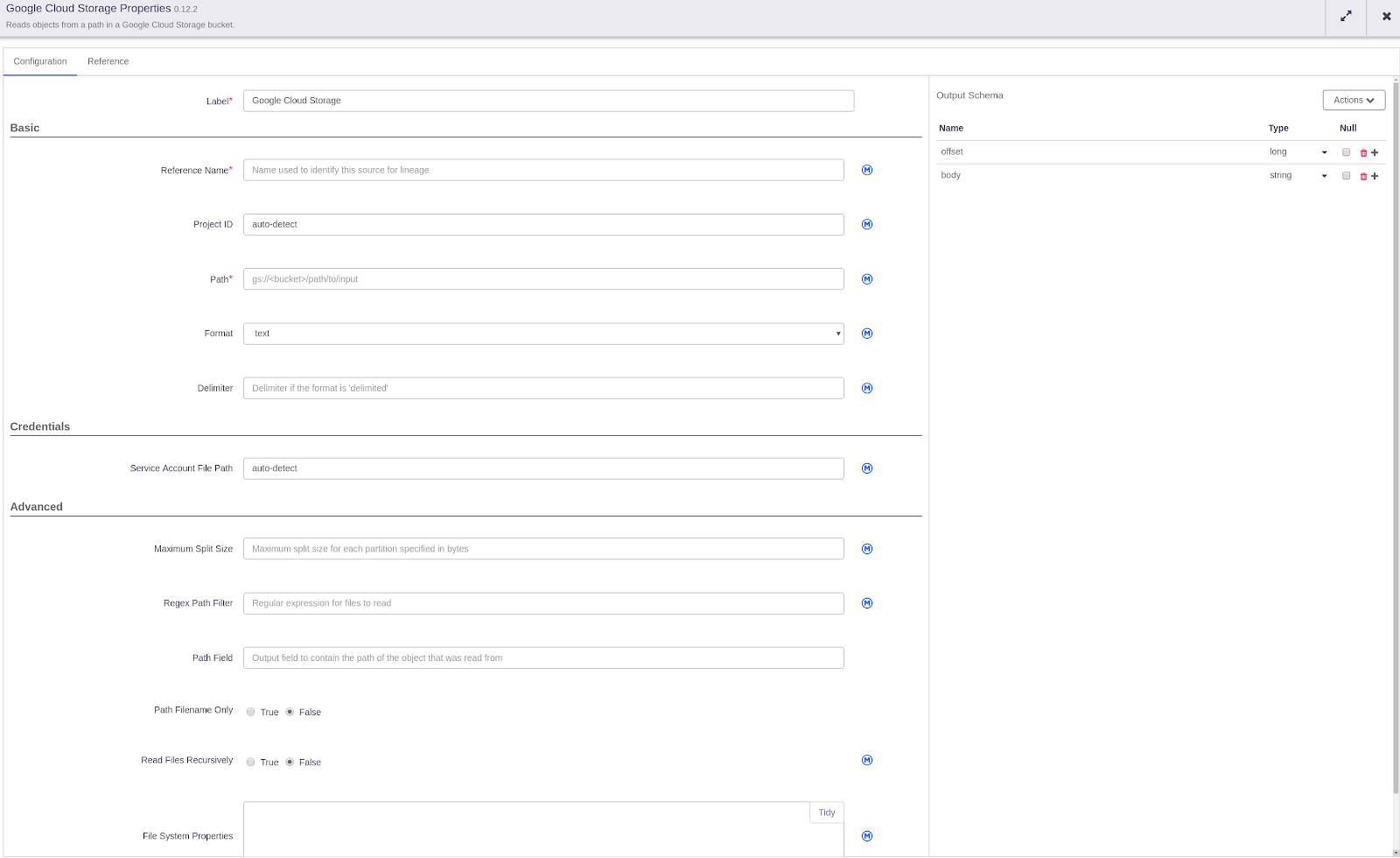 Google Cloud Storage Properties
Google Cloud Storage Properties
For example if you have your data in Google Cloud Storage, you have to provide a label and reference name. Then you can either select you Project ID or keep it in automatic to be detected automatically. You’ll have to provide the path to your bucket in which your data stays, and that’s it.
Pre-built or custom Transformations
If you’re creating an ETL (Extract Load Transform) pipeline you can also perform some transformations using pre-built transformation plugins. Or you can create your own transformations. Another interesting option is to use Data Wrangler to perform data cleaning, formatting etc.
In the Analytics section you have options to Deduplicate, Group by, Row normaliser, Find distinct values or Data joiner. Which is super handy since these are very general transformations which are performed quite often.
Sink Tab
After deciding on your transformations you can choose to save your transformed data into a Sink. For this you can use one of the predefined options from the “Sink” tab. In that tab you have options such as:
- BigQuery
- Google Cloud Storage
- Google Cloud Datastore
- Google Cloud Pub/Sub
- Database
- Hbase
- Avro
- Amazon S3
- Etc.
In addition to this, if you want to create or delete a bucket from Google Cloud Storage or move the data contained in it, you can easily do this through your pipeline using the relevant plugins.
In this Sink tab you also have the option to use “Remote Program Executor” which basically enables you to run your own code from a Virtual Machine. For example, if you have a custom Python code or Bash scripts you want to run you can create a VM and give access to Cloud Data Fusion so it can access it through SSH and execute the code that resides there.
Error Handlers and Alerts Tab
In the Error Handlers and Alerts tab you can trigger alerts and run error collector to keep track of the errors in the process.
Pipelines List
After you’re satisfied with your pipeline design you can save it and click on deploy to have it readily available for execution in production. After you deploy your pipeline design, it will be available in the Pipelines List.
 Pipelines list in a namespace
Pipelines list in a namespace
If you just want to duplicate, export or delete your pipeline design, you can perform these actions from the pipelines list.
Data Wrangling
 So you also want to wrangle your data? Of course you do… If you not only want to replicate your data from an on-premise source system to a data warehouse in the cloud like BigQuery , but also clean it by manipulating it to extract the information that you need, you can use a great tool in Google Cloud Data Fusion called “Data Wrangler”.
So you also want to wrangle your data? Of course you do… If you not only want to replicate your data from an on-premise source system to a data warehouse in the cloud like BigQuery , but also clean it by manipulating it to extract the information that you need, you can use a great tool in Google Cloud Data Fusion called “Data Wrangler”.
Using this tool will make your life a bit easier, as you don’t have to write all these long SQL queries to perform all the cleanups and joins.
In Data Wrangler, you can clean and manipulate your data with just a few simple clicks. You can then save this Data Wrangler recipe to use in your data pipeline processes.
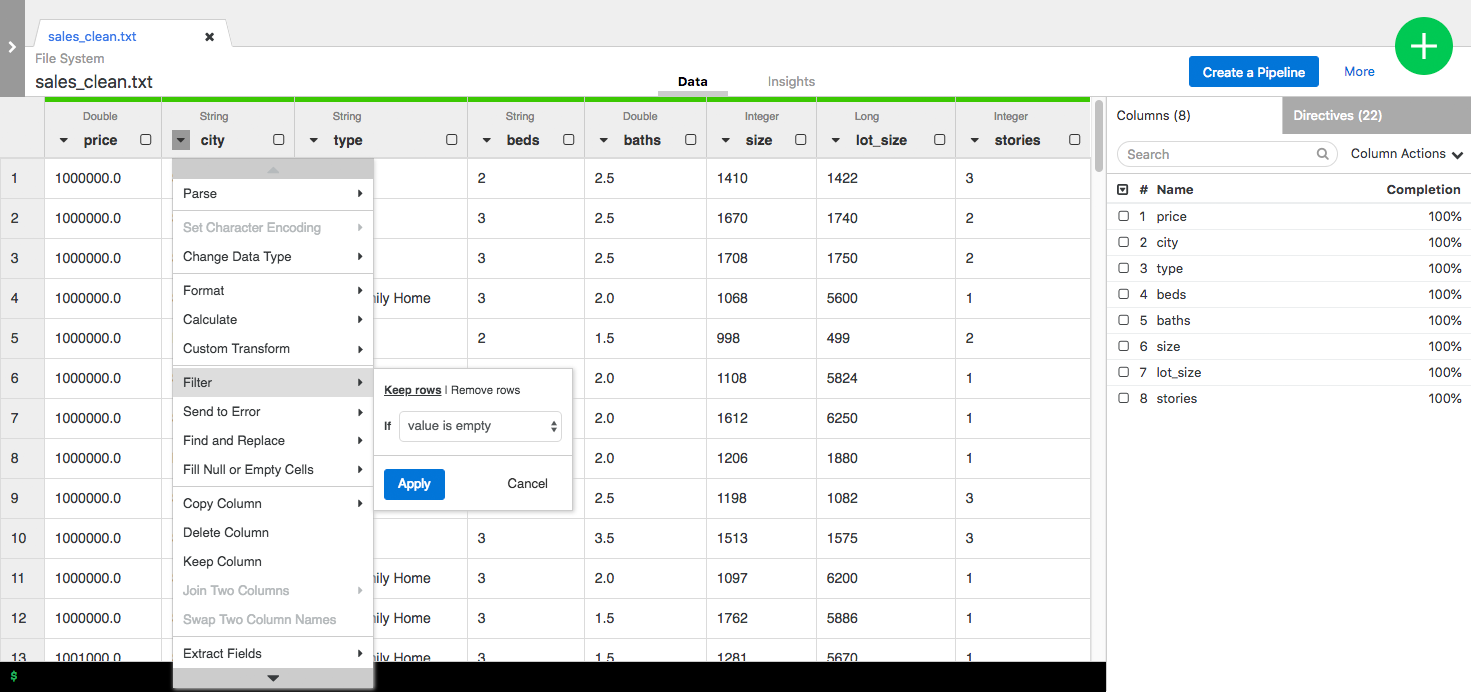
With Data Wrangler in Cloud Data Fusion you can select a column, apply a filter to it, change the format and copy or extract fields from it with just a few clicks. Each step you applied is saved so you can go back and modify them in any step of the data wrangling.
After you are satisfied with the steps you can just click on ‘create pipeline’ and it will automatically switch to the Pipeline Studio. So you can directly use the data wrangling steps you just created and operationalise effortlessly into production pipeline.
Scheduling your pipeline
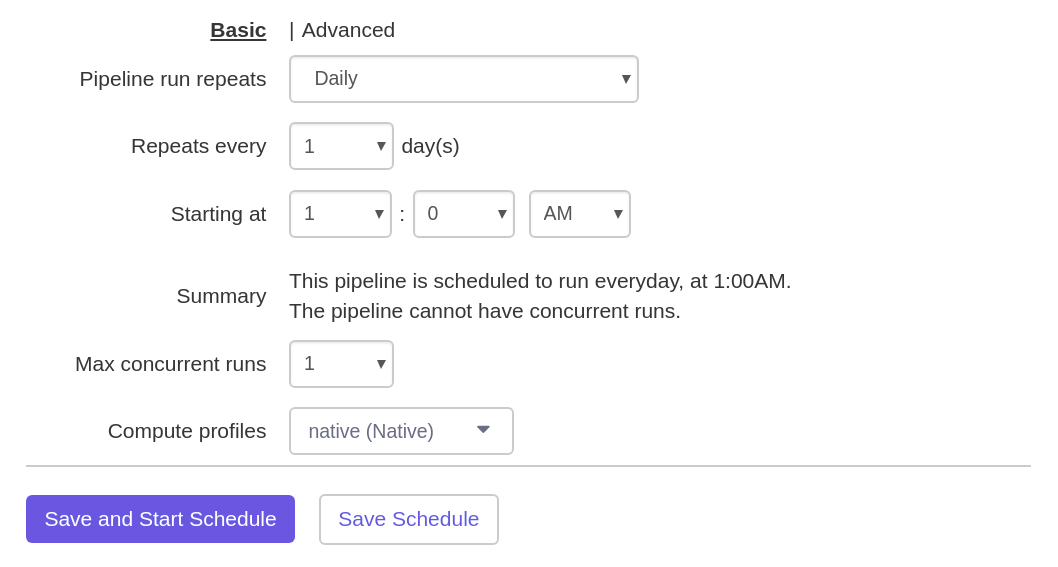
After you created your data pipeline and tested it, making sure that it works without any failures, you now want to schedule it.
Doing so, it will run on a regular basis and do its magic to ingest and clean your data into BigQuery. Great thing about this is that you can also do the scheduling of your pipeline with just a couple of clicks in Google Cloud Data Fusion!
Exporting Your Pipeline
Better safe than sorry, right? Indeed, I also think so. If you want to export your pipeline in order to have a backup or to be able to use it in your CI/CD pipeline later to automate all these processes, Cloud Data Fusion provides you with a JSON export of your pipeline.
Plus all the pipelines can be parameterised. So if anything goes wrong with your cluster and you lose all your pipelines, you can just import them and have your pipelines back in place, ready to be executed again for production quickly.
Be careful though, currently there is no way to automate this backup process. So you need to manually back them up one by one.
Pros and Cons
After using Google Cloud Data Fusion for a while on different projects, I got to know the service better and better. There are great things about using it, as well as some limitations that you will probably encounter. These are the pros and cons in my opinion:
Pros
- Easy to use, visual interface
- Fully Managed
- Enables you to connect to many different data sources easily
- Fully Scalable
- Fully Distributed
- Flexibility to have all the pipelines as code
- Exporting your pipelines as code
- Enables you to use Rest API calls to create and trigger pipelines
Cons
- Not being able to use Cloud DataFlow (yet!)
- No automatic or scheduled backup of all pipelines possible (yet)
- No autoscaling
“We are moving slowly into an era where big data is the starting point, not the end.” – Pearl Zhu, author of the “Digital Master” book series.
Conclusion
Besides being a visual tool, Cloud Data Fusion enables you to extract every step of your pipelines to have as code. In this way, you can easily use tools such as App Engine or Cloud Composer to automate all the pipelines. All the Spark or MapReduce code is created for you. So you don’t have to deal with writing all the code necessary for each process. Plus it uses the power of Cloud Dataproc and manages it for you.
Google Cloud Data Fusion is a relatively new tool and still in beta, so there is still room to improve. Google Developers are certainly working on improving it as I am writing this blog post now.
If you’re already familiar with MapReduce or Apache Spark, even better. You can use these technologies to create your pipelines easily with Cloud Data Fusion. But if you want to use Cloud Dataflow (Apache Beam) as an execution environment, it is not available at the moment. Soon enough, hopefully it will be possible to use Cloud Dataflow as an execution environment as well.
Do you want to give Google Cloud Data Fusion a try? To get you started, I suggest you to go through the 2 steps below:
- Check out the Google Cloud Data Fusion Quick Start Google Cloud documentation
- Test Cloud Data Fusion yourself with this tutorial by Google
To conclude the two parts of this post on how I used Google Cloud Data Fusion to create a data warehouse – I can say that Google Cloud Data Fusion is the tool for you if you don’t want to deal with coding and just want to create data pipelines. With Data Fusion you can create, visualise and export data pipelines while not having to think about how to manage your clusters, nor about scaling or distributing, nor about how to connect with different data sources, nor about writing your own connectors for them.
Happy data crunching!

