This article is written by Rik Pauwels, Senior Data Architect at Devoteam G Cloud
With data becoming more widely available a lot of businesses are wondering how they can make sure employees and clients don’t see too much data. It happens a lot that when an employee asks for access to a piece of info they get access to the whole table where that piece of info lives but this is simply wrong. Department managers don’t need access to the costs of all departments if they just want to analyse the costs in their own department. To limit the risk of data leakage and data exfiltration attacks this article sums up three ways to achieve row-level security on your BigQuery data warehouse
Overview
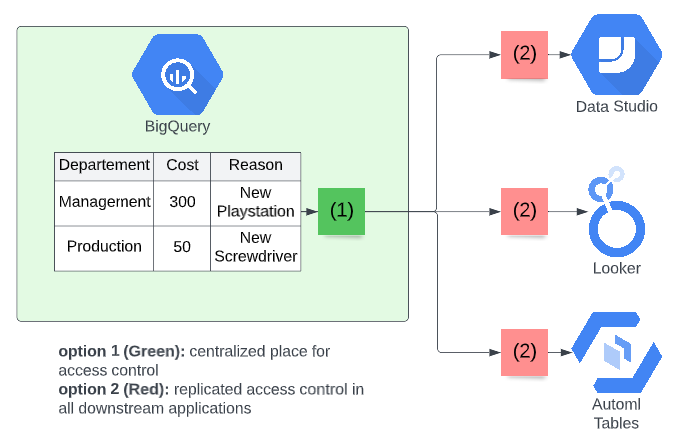
In high-level terms there are two ways to implement data access control; either you apply it directly onto your data warehouse, in this case, BigQuery, or you apply it to every downstream application (Data Studio, Looker …). While the option of giving it in the downstream applications is sometimes a very viable option, most companies come back to it when their data landscape grows because of the following reasons:
- This logic needs to be replicated in each new tool.
- When migrating to new tools the access logic needs to be rewritten from scratch.
- Verifying who has access to which data is hard because all downstream applications must be analysed by the application security experts.
- New access policies take a long time to implement on all downstream tools.
For these reasons, this article focuses on the option of giving access directly to the data warehouse so the access policies are propagated to each downstream tool. Because these access policies will determine which rows of the data warehouse can be seen by who, often all solutions are named “Row-level security”. The figure below illustrates the concept and will be used in the concrete implementations.
Solution 1: Authorized views
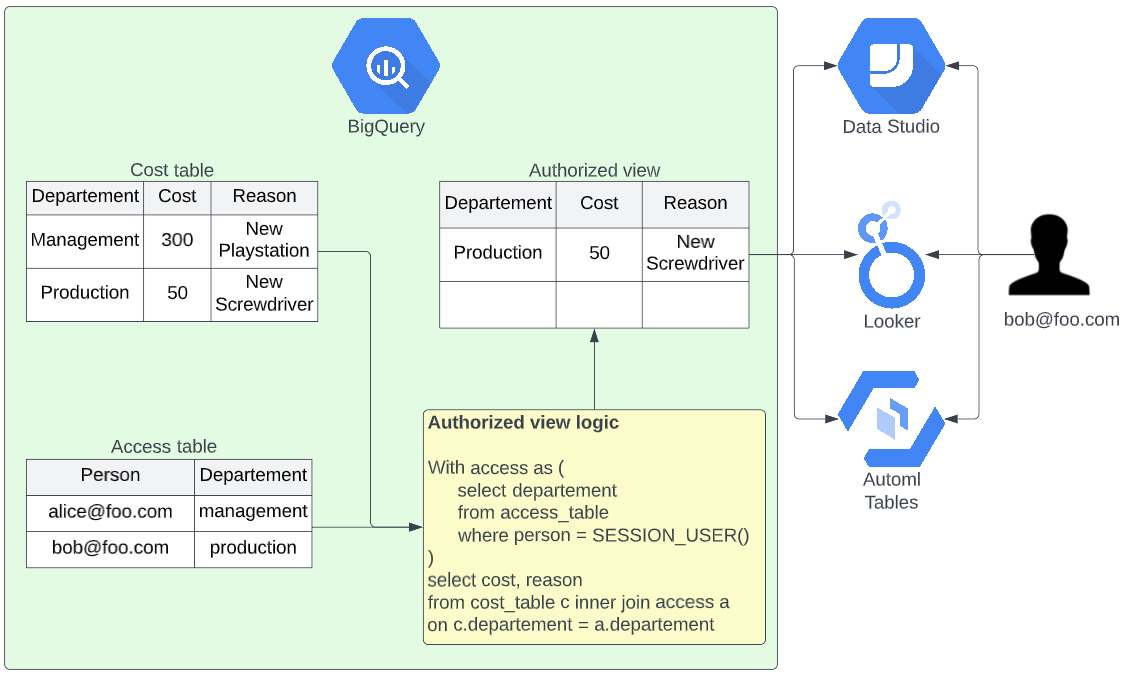
The first option is to use BigQuery’s Authorized views. Authorized views are fundamentally not different than regular views in BigQuery. The only difference is that you give this view extra permissions to access data on locations that the user of the view is not authorized to view.
In the example below (figure 2) you would give data analysts read access on the authorized view but not on the cost table. On top of that, you would give the authorized view access to read the cost table. The data analyst can now read from the authorized view and not the cost table.
On its own, this view can hide some columns or pre-aggregate data of which the details can not be known but it is not true row-level access since the user can still see all data from all departments. The row-level access only comes when you are using the SESSION_USER() function of BigQuery. This function returns the email of the user that created the request. This email, in combination with an access table, will give you fine-grained row-level access.
Bonus Tips:
- For better performance and lower costs it is recommended to cluster the access table on the person column.
- When people can have access to multiple departments it is best to place them in an array per person to improve read operations.
- Filter the access table first before joining it with other tables to make joins more efficient.
- The access table can be replaced by a user-defined function (in SQL or Javascript) if it is easier for you to define access policies that way.
- The access table can also be replaced by a remote function (e.g. Google Cloud Function) but keep in mind that a GCP project can only handle 10 concurrent BigQuery jobs that use remote procedures (source) so this option might scale poorly depending on the setup.
| Pro | Con |
| Very customizable | Creation of the access table might be hard as you can not use Google Groups directly in the table. |
| No limitations on the number of users in the access table. | |
| Single point of data access for all downstream applications. |
Solution 2: Row-level security BigQuery
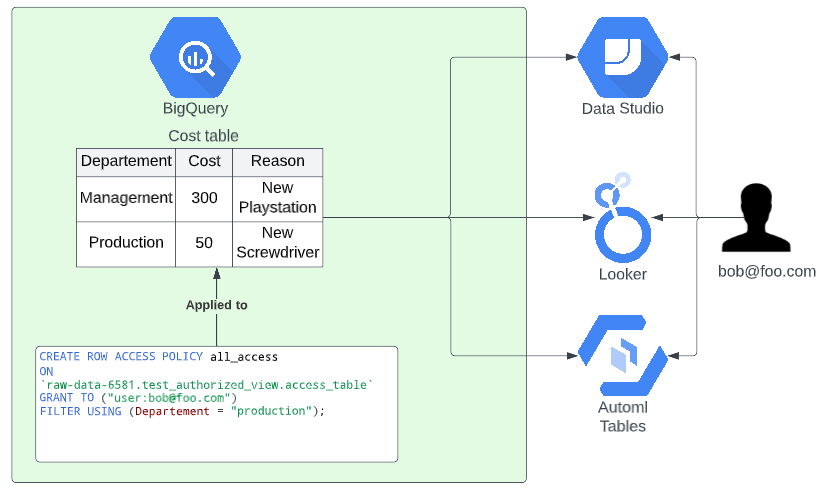
Google recently released a new BigQuery feature called row-level security which enables data security engineers to add access policies directly on the base table itself. This means you don’t have to maintain other data assets than the table itself.
Adding access policies to tables can be done via SQL DDL statements and can target various cloud IAM entities like users, groups, domains, service accounts etc. Whenever someone of that domain, group .. reads the query the access policy statement is added by BigQuery and they will only see the data they are allowed to.
At the moment of writing, you can specify up to 100 policies per table, the policies can only use native BigQuery functions and do not support subqueries.
Bonus Tips:
- The row-level security feature was only released recently so it comes with some limitations. Please read up on them when considering this approach.
- Most notably: the access policies don’t take part in partition pruning so even though you partition or cluster on the columns referenced by your access policies. When you query, you will get billed on all the rows in the table for all columns referenced in your access policy.
- Make sure your access policies are defined in code so that when the table gets recreated you can automatically apply them back.
| Pro | Con |
| No data duplication | Limited in logic |
| No additional setup required | Policies are table attributes so they will be removed if the table gets recreated |
| Single point of data access for everyone |
Solution 3: Leveraging Flycs to create dedicated data marts
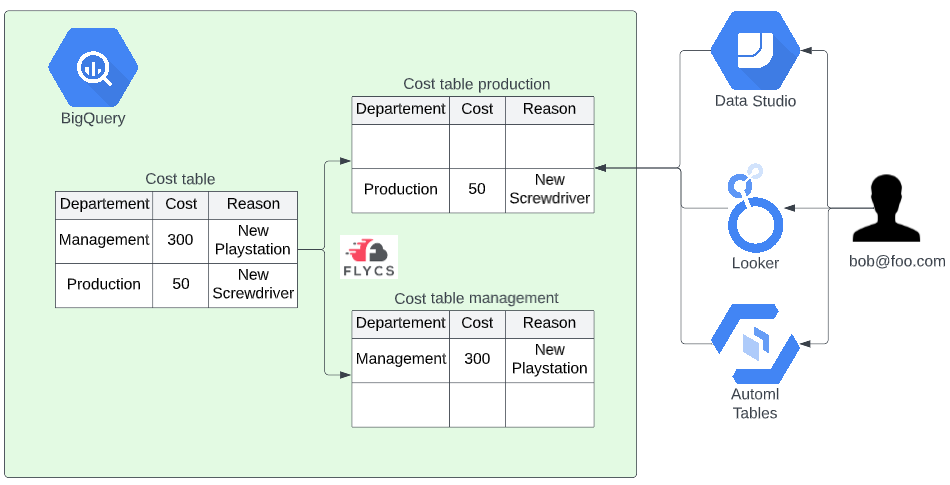
The last option is to leverage a data warehouse framework like Flycs to automatically create dedicated tables for people in different departments. This is the most secure and flexible option of the three because you can use python and SQL to determine what data should go where. Because the data is split before people read it they can not perform side-channel attacks against the base table. It will also increase query performances since filters and aggregates are already precomputed.
This option has a drawback, however: there is no single point of data anymore. This means that for example dashboards can not point to one generic table or view, it should point to the table that has the data of that department.
| Pro | Con |
| Fast reads | No Single table to access for all data |
| No limitations on how many users | |
| Not susceptible to side-channel attacks |
Conclusion
Row-level security can be achieved in multiple ways but there is no one solution that works best in all cases. It might even be possible that the best solution for you is a combination of the options listed above. You can for example split the company-wide cost table per department using Flycs and then let the departments define authorized views or row-level security policies on the exports to further manage fine-grained access control for teams in their department.
If you are purely interested in column-level access, for example removing PII data from a dataset, but don’t want to create authorized views, I would suggest exploring yet another security feature of BigQuery named: column-level access control. This also works well together with the row-level access described above.
Take your time to think about a solution that works in your case and think about how you will (1) add new policies (2) remove added policies (3) track who has access before going full force for the first option you see online. Security can sometimes be hard, but undoing a data leak is much harder.
Do you prefer to talk to an expert or would you like some help? Devoteam G Cloud has the expertise to get you on track.

