With the emergence of big data and the need to get insights from many different systems as quickly as possible, it is more crucial than ever for businesses to have a data warehouse that tells you the full story about your data.
- You want to have all data in one place and enable any department in your company to access the data and insights it needs, in just a few clicks. Easier said than done, as the outside world is full of buzzwords and technologies that can be overwhelming when it comes to building a data warehouse.
- Where do you start? What tools should you use? These are complex questions to which we have defined time-saving answers.
- In this article, we will describe a data warehouse accelerator solution that we have built on Google Cloud: Flycs. This solution encompasses the best practices we have accumulated over five years of data engineering projects on Google Cloud.

Data Warehouse Modernisation on steroids with accelerator frameworks Flycs
- Grasp the full concept of Flycs during this 25-minute session
- Session by Edgar Ochoa, GCP Cloud Engineer. Presented during the Devoteam G Cloud Day 2022 in the UK.
Data warehousing can win games; data warehousing on Google Cloud can win championships
If you want to accelerate your data warehouse project with top-notch technologies and avoid common pitfalls, carry on reading.
1. Some context about data warehousing
Over the years, our team of consultants has worked on various major data warehousing projects on Google Cloud. We developed an automated tool that integrates all the best practices required to build a data warehouse on Google Cloud. This automated tool can be seen as a framework that we will refer to as “Flycs” in the rest of this article.
Building a data warehouse on premises or on any cloud can be daunting and requires many different skills. The challenge does not lie in the technologies, as Google Cloud offers all what is required to build a powerful and efficient data warehouse.
The challenge lies in how to use all of these tools together and make sure that each tool communicates efficiently with the others.
2. Making data warehouse tools communicate with each other
An end-to-end data warehousing project in the cloud consists of three main stages: the ingestion stage, the transformation stage and the distribution. Let’s take a closer look at each of them.
2.1. Ingestion stage
In the ingestion stage, your data needs to land on Google Cloud Storage (GCS) or BigQuery somehow. This stage encompasses the whole system needed around this ingestion.
Two families of ingestion exist:
- Batch: data is loaded periodically
- Stream: data is loaded continuously
Each one requires a slightly different architecture and set of tools. Batch ingestion is easier to implement, as it can be as simple as upload of CSV files on a GCS bucket. Streaming data ingestion, more sophisticated and more suitable for real-time situations, requires more complex tools like Dataflow or the use of a third party solution like for instance Alooma or striim.
2.2. Transformation stage
In the transformation stage, your data needs to undergo a set of transformations before landing into well structured data marts that will face your consumers.
2.3. Orchestration of your transformations
This stage is the most delicate and complex, in the sense that it involves a lot of different activities and tools that need to be well tied together to work in harmony. Some of these activities include the orchestration where you need to ensure that your transformations run in the right order.
While it’s easy to orchestrate a few queries, this can become quickly complex once your data model deals with big data and becomes something like this:

You obviously need a systematic way to approach the orchestration.
Abstracting activities to focus on the insights
The same happens for versioning, configuration management, data quality, Personally Identifiable Information management, etc. All those activities are cumbersome and can actually be abstracted, letting you focus on what matters for your company: the insights.
The pie chart below represents all those activities, with the blue zone being the activities that can be abstracted away by leveraging a well-designed framework like Flycs.
The orange part represents the part that is specific to a particular company.
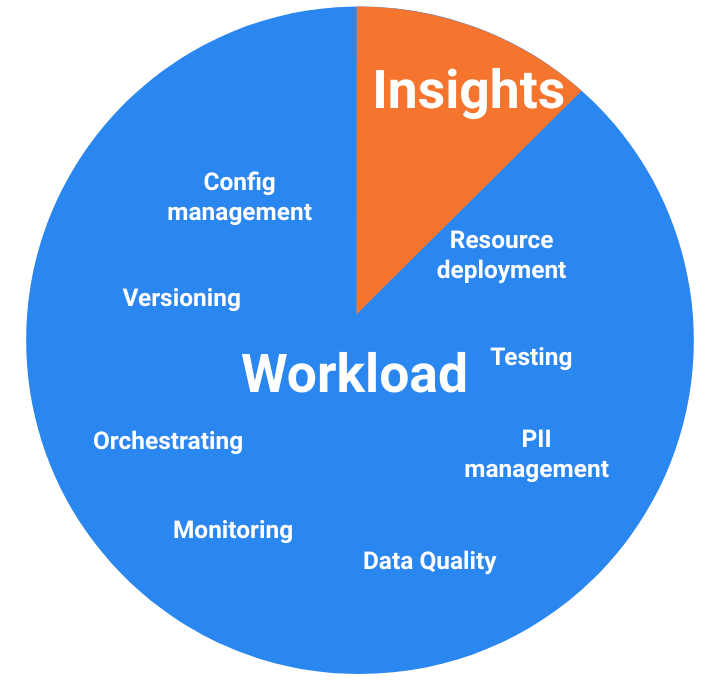
The automation of all these workloads by leveraging a data framework like Flycs significantly reduces the amount of expertise your team needs.
More importantly, it lets you focus on the data modelling of your data warehouse and the SQL transformations to meet the model. And to move your data from the landing area until the data marts.
2.4. Distribution Stage
In the distribution stage, once your data is in well-defined data marts split by business logic, it needs to be shared/distributed to internal departments, business partners and the outside world. This data can then be used to build BI dashboards, machine learning models, etc.
A new use case is also to have these data marts behave as data sources for microservices. And to build an API around each one of them, to easily distribute the data, instead of having the consumer to plug in into the BigQuery data marts directly.
These three stages with a conceptual overview of the different data layers within the transformation stage is depicted in the visual below.
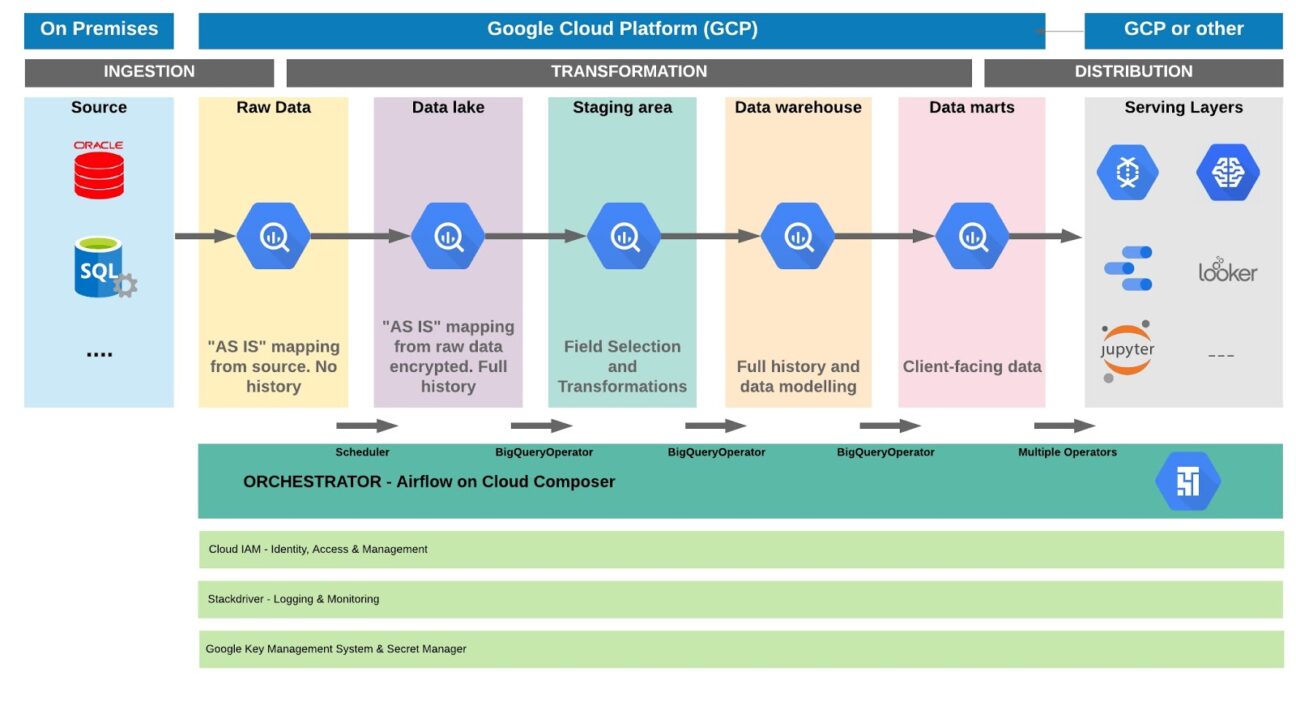
2.5. Data transformation with BigQuery SQL
Our experience has demonstrated that pretty much any data transformation is possible through BigQuery SQL. Therefore, we leverage BigQuery all along our transformation stage.
It allows the end users to only focus on BigQuery and to master its specific SQL (fully compatible ANSI 2011 SQL on top of additional features such as nested fields) in order to get the data from one data layer to the other. This may seem like a limitation, but the returns are quite high.
By using only SQL, Flycs is able to automate some of the hardest tasks in Data engineering for you. Data lineage and encryption are for example fully handled for you automatically.
Last but not least, the Flycs data warehousing framework is agnostic of any data modelling and lets you have the total freedom of building for instance a data vault or a star schema. The data layers depicted in the schema above are also flexible between the raw data and the data marts. You might want for instance to skip the staging area.
3. What the Flycs data warehouse framework solves
- Saving Precious Time
- Ensuring replication and consistency
- Eliminate the need of expertise on specific tools
- Data Governance
- Data Security
- Regulation & compliance
- Single Source of Truth
- Monitoring
3.1. Saving you precious time
Believe us, if you endeavour to build a data warehouse on Google Cloud, you will end up doing all these complex and indispensable tasks mentioned in the pie chart above. These tasks are founding pillars for the transformation stage. And only with these strong foundations, you will be able to build your data warehouse.
Many companies underestimate these tasks (or move over them too quickly) and end up losing much more time further down the road. Our goal here is to accelerate the time-to-value for your company to get its data to the data marts layer.
3.2. Replication and consistency
The idea of Flycs is also to put software and DevOps engineering principles into cloud data engineering. This is done by bringing a state-of-the-art DevOps ecosystem into the game. This ecosystem will give you the power to:
- version your transformations. This enables easy rollbacks and different environments to be on different versions.
- handle multi-tenancy. You might end up with various data warehouses for different countries. The Flycs framework lets you do that easily through advanced configuration management. You’ll be able to set up different configurations, but have one centralised DevOps project that manages it all.
- put all your infrastructure as code (IaC). Any data project involves its part of infrastructure and you better want to have it as IaC in order to easily recover any failing part and avoid human errors.
- have a fast CI/CD pipeline in order to iterate quickly on new code. You want to see quickly how your queries are orchestrated and run within your data project. This is done through a complete CI/CD pipeline that will test your code and deploy it in a matter of a few minutes.
- have isolated environments. What if you are a team of 20+ data engineers that need to work with Flycs?! You need each one of them to have its isolated sandbox environment to run their queries without interfering with other colleagues. Flycs will give you this freedom through easy git workflows. An end user branching out on a branch that is not “develop”, “release” or “master” will automatically be under an isolated sandbox environment under his name. And a whole set of resources will be created for him/her to test the code (for example specific BigQuery tables, specific Airflow DAGs on Cloud composer, etc.).
Having this DevOps ecosystem working for you behind the scenes will bring your development to another level while making your engineers strive on what really matters; the business logic around your data.
3.3. Need of specific expertise
The orchestration engine on Cloud Composer, a parser for automatic data lineage using Zeta SQL, a DevOps ecosystem (Gitlab, SonarQube, Spinnaker) hosted on Kubernetes, Terraform for IaC and Data Catalog for data Governance are all tools that you will eventually want to use.
That is, if you want to build a proper data warehouse on Google Cloud. Below is an overview of some of these tools:

Our goal has been not to build some black magic but really to get the best out of each of these components for the sake of building an efficient data warehouse on Google Cloud.
Complexity does not lie in each of these components individually, but rather in how to glue them together to have a consistent solution.
In the end, this is the workflow that an end user will have:
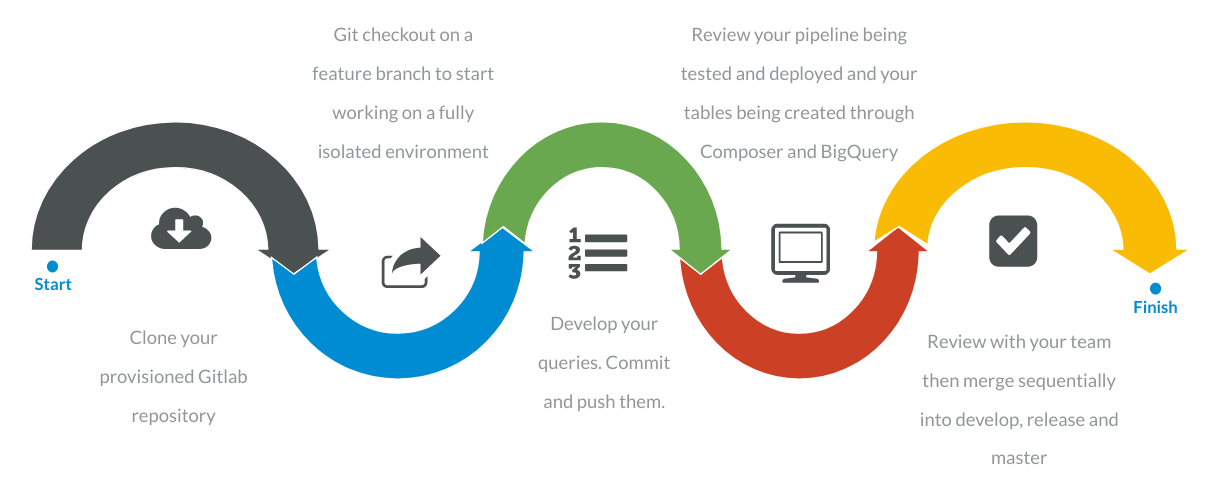
As you can see, this workflow is quite simple and enables your team to directly start writing data transformation queries once the Flycs data warehousing framework is installed on your Google Cloud Platform projects.
3.4. Data Governance
You cannot deal properly with big data if you don’t have a sound Data Governance framework defined. Three areas define data governance:
- Securing the data
- Regulations and compliance
- Visibility and control
3.5. Securing the data
Our Flycs framework tackles the first point by encrypting all PII data from the data lake layer until the data mart layer (see chart above). Once the raw data lands on BigQuery just after ingestion, a data owner/data steward is required to input a series of tags for all the data (table and column level) through a Google sheet that will then post the tags to Data Catalog.
A very summarised architecture of this process is depicted below (a real architecture involves some Cloud Functions for validation, an App Engine service for approval process, etc.)

One of the important tags for securing the data is the boolean “PII” tag at column level that indicates if the column contains PII data or not. All the queries referring to columns that have PII tags set to true will automatically encrypt the data through AEAD (built-in encryption functions within BigQuery) along all the data layers.
If the data needs to be decrypted at the data mart layer, it is then decrypted using its appropriate AEAD decryption key. All the complexity of encrypting and decrypting the data is taken away from you. The only manual step is tagging the data at raw level.
3.6. Regulation & compliance
By using AEAD, Flycs also tackles the second point of complying with various regulation policies. For instance, the right to be forgotten by an individual can easily be achieved by removing the keyset of the individual.
Without the key to decrypt the data for this individual, his or her data (even in all backups!) are meaningless.
3.7. Visibility & control in a single source of truth
The third point of Data Governance is tackled by centralising all the metadata/tags about your BigQuery tables within Data Catalog. You need to have one source of truth accessible by all your employees and your orchestration engine to determine what is inside each table.
Data Catalog is fully integrated with BigQuery and by having a data owner feed it metadata through a Google Sheet with pre-built tag templates, the framework can automatically propagate these tags to further data layers. This is achieved by parsing your SQL transformations for you.
This ensures that your Data Catalog is up-to-date at all times and gives full visibility to your end users.
3.8. Monitoring
Last but certainly not least, a big part of the data warehousing framework deals with visibility through monitoring. We want end users to have full visibility on what’s happening at every stage and in every module used.
This visibility is achieved through:
- Access to CI pipelines (open-source Gitlab)
- Access to CD pipelines (open-source Spinnaker)
- Data Studio Dashboards for BigQuery. These dashboards will show you in detail all your activities in BigQuery (how many slots you consume, what queries cost you the most, which users are running what kind of queries, etc.)
- Data Studio Dashboards for Cloud Composer. This will let you visualise the dags you are running, how greedy they are in terms of CPU consumption, the workload activity of your Airflow scheduler and workers, etc.
- An alerting system. If anything goes wrong anywhere, proactivity is the norm. You will be informed immediately through an email or a messaging tool (either Slack or Google Chat).
This monitoring, on top of knowing at all times what is going on, will also help you in decision making. As an example, imagine you notice BigQuery has an average consumption slot above 500, this is a good signal to move to a flat rate pricing schema.
If you notice your scheduler being constantly close to 100% CPU utilisation, this is a good signal to scale up your instance. Flycs will notice it for you, but some final decisions that have a cost impact remain up to you. For instance, scaling up vertically the scheduler instance of Cloud Composer.
Interested in this data warehouse accelerator framework? Curious to see what it can mean for your business?
We hope this has given you a good taste of the solution we have built here at Devoteam G Cloud and which was born from building various data warehouses on Google Cloud. The framework is giving organisations access to an automated, faster way to set up their data warehouse on Google Cloud while making replication, monitoring, visibility for end users and data governance easier than ever. Flycs framework allows businesses to focus on what really matters: getting the most value out of your data.

Get in touch with
Mark De Winne
Google Cloud Business Developer at Devoteam G Cloud

