What is a data lake?
Before answering the question of what the best data lake platform on Google Cloud is. It is important to first talk about the definition of a data lake and where it differs from a data warehouse.
There are a few data lake definitions out there but for this article, we will go with the definition of Google which states:
“a data lake is a centralised repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits.”
Differences between a data lake and a data warehouse
Keeping this definition in mind we can see the differences between a data lake and your typical data warehouse.
- A data lake hosts all kinds of data and not only structured data like a data warehouse.
- A data lake stores data in the exact format that it got from the source and not in a prepared enterprise data warehouse schema.
- The last difference is that it will likely host a lot more data than the data warehouse so scaling in terms of storage capacity is even more important.
So, where should I make my data lake?
Now that we have a common definition of a data lake we can tackle the question of what platform is best. As with a lot of things in life, the answer to this question depends on the environment where you pose the question. If you have a lot of unstructured data like pictures and videos then your requirements will be different than when you want to unify a lot of events and transactional databases.
To make this article as valuable as possible for everyone we will compare 3 Google Cloud Services (Cloud Storage, BigQuery, Cloud SQL) and show you what the strong and weak points are of each service with respect to the requirements of a good data lake platform so you can see which platform works best for you company.
If you already know the basics of these services please continue to the next section. For the ones that need a refresher:
- Cloud Storage stores data as ‘blobs’ (binary large objects) inside a ‘bucket’. A blob can be anything (a file, video, operating system image…) but you can only act on the blob as a whole. E.g. you can not get the first page of the file, you can only get the entire file. Cloud storage works with a distributed storage engine so you can easily scale to petabytes of data.
- BigQuery stores data in column-oriented database tables where attributes are separated by columns. BigQuery works with decoupled storage and compute infrastructure so you can very easily scale to petabytes of data.
- Cloud SQL stores data in row-oriented database tables where attributes are separated by columns. Cloud SQL does not work with a distributed storage engine so scaling this up becomes a problem when you surpass 1 TB.
Data should be storable
It all starts with (1) getting data from where it is produced and (2) storing it in the data lake platform. While you can easily write a book on this topic alone I want to be as concise as possible.
Unstructured data
If you have unstructured data, then there is a high chance you will use something similar to Storage Transfer Service. This service can natively pull data from other public clouds, filesystems or URL’s. BigQuery and Cloud SQL are not designed to store unstructured data objects so they are not an option, not even if you really want to.
(Semi-)structured data
If you have (semi-)structured data coming from APIs or database tables, chances are high that you will work with an ETL tool such as Datastream, Fivetran or Airbyte to load data into your data lake. A lot of these tools can natively push data as-is into BigQuery as well as Cloud Storage but I recommend going with BigQuery. The reason is that data in BigQuery is a lot easier to visualise, manage and work with. On top of that, directly syncing data into BigQuery removes the need of writing custom code to move data from your data lake in Cloud Storage and your data warehouse in BigQuery.
If you have rapidly changing structured data it is sometimes even best to create a read replica of your operational database in Cloud SQL instead of relying on another data replication tool to keep your data in BigQuery in sync. Why? This way of replication can be cheaper than using another tool like Datastream when the data in your database changes a lot. The pricing model of these Change Data Capture (CDC) tools is mostly based on the number of rows that are replicated to another source so a lot of changes mean a lot of costs.
Event-based data points
The last data type are the data points that are published in the form of events. Those events can easily be captured by PubSub and natively ingested into BigQuery. You can also store the events in Cloud Storage if you use a Streaming Dataflow pipeline. But again, data in BigQuery is a lot easier to work with than data in Cloud Storage, so I advise you to follow the BigQuery route.
| Kind of data | Get data | Store data |
|---|---|---|
| Unstructured | Storage Transfer Service | Cloud Storage |
| (Semi-) structured | Datastream, Fivetran, Airbyte.. | BigQuery |
| structured, highly volatile | Cloud SQL replication | Cloud SQL |
| Event based | PubSub to BigQuery, Dataflow | BigQuery |
Data should be discoverable
If your end-users can’t find the data, then the whole story stops. Exposing an interface to easily search for data is maybe not a requirement of a data lake platform, but it should at least be able to expose its metadata to another data governance framework used in your organisation.
Cloud Storage stores data as blobs in buckets. Most of the time, related data is stored in the same bucket or subfolder within a bucket to enable easier access management. Over time you will gather a lot of blobs and you will notice that it becomes quite painful to find interesting objects back.
It is possible to search a blob by name if you know its name and in which bucket it is stored but it is not possible to look for something inside of a blob to get for example all the blobs that contain revenue data. This is because Cloud Storage has no knowledge of the content of its blobs, like the columns of a CSV file. It is possible to set metadata on blobs in a bucket but unfortunately, this information is not available in Google Data Catalog so you need other 3rd party services to expose this data to end users. But be careful, not all data catalogue solutions natively support Cloud Storage.
Exposing metadata from BigQuery on the other hand is very simple. All bigger data governance platforms can natively read metadata from BigQuery and sometimes even deduce data lineage from the BigQuery job logs. Furthermore, BigQuery does not work with data objects but with tables so it is even possible to search for a specific column without knowing the exact name of the table or dataset.
| Platform | Finding data will be… |
|---|---|
| Cloud Storage | Hard to scale |
| BigQuery | Easy |
| Cloud SQL | Easy if you put additional tools in place. |
Data should be secure
When you start sharing and publishing data for consumers you have to make sure that you don’t share too much! Today, most data breaches happen via stolen user credentials. So don’t rely on the goodwill of your employees to only access the data they should access. If their credentials are stolen, all of the data they can see can potentially be stolen or leaked.
The access control in Cloud Storage at bucket level works natively with Cloud IAM. This means you can use the same security groups you normally use. This is a big plus because you don’t have to manage additional groups or user policies. You can also define more detailed blob-level access control lists (ACLs) but these are harder to maintain so Google recommends against using this. This means that in general people will have read or write access to all the content of a specific bucket or not.
Access control in BigQuery is very elaborate and also works natively with Cloud IAM. You can give people access to specific projects, datasets (= collection of tables), tables and even specific columns within a certain table. You can also apply row-level security and even dynamically mask your data based on who is accessing the table. This means you can provide and manage access at scale down to the row and column in the table for all users in your organisation.
The access control in Cloud SQL is based on the access control of the database instance that you run. For example, if you run a MySQL server then it is up to you to configure users inside the database. That is a lot of work at scale.
| Platform | Securing data will be |
|---|---|
| Cloud Storage | Easy to do at a granular level |
| BigQuery | Easy to do at all levels (granular & super detailed) |
| Cloud SQL | Hard to scale |
Data should be usable
Now that people can access the data and can find what they want, we must make sure they can also use the data efficiently. In this section, we will discuss how people will be able to work with the data lake data by discussing the integration with the most used analytics tools of Google: Google Sheets and Looker Studio.
Data blobs in cloud storage must be downloaded entirely and manually loaded into a Google Sheets or MS Excel every time you want to access that data. Especially when the loading requires some pre-processing (like renaming headers) or type conversion. This can be quite cumbersome and people will get tired of it pretty fast. Looker Studio can also connect to Cloud Storage directly but can only work with CSV files.
BigQuery natively integrates with both Google Sheets and Looker Studio. In Looker Studio you can easily connect to every table you have access to and in Google Sheets you can directly execute and get data from BigQuery within a Google Sheet. BigQuery also integrates with Vertex AI Workbench for data science and AI purposes.
Looker Studio can also connect to Cloud SQL out-of-the-box but requires data downloads and manual imports to work together with Google Sheets or Excel.
| Platform | Using data is… |
|---|---|
| Cloud Storage | Hard |
| BigQuery | Easy |
| Cloud SQL | Easy for dashboarding, hard for sheets |
Compliance with laws and regulations
During the last few years, governments are enforcing tighter data regulations like the right to be forgotten. This has a direct impact on your data warehouse but maybe even a bigger impact on your data lake. Data lakes store data in various formats and schemas so without proper governance it will be very difficult to find the data that you should delete or mask.
When using Cloud Storage you can leverage Cloud Data Loss Prevention (DLP) to scan objects in a bucket to redact or flag sensitive information like credit card numbers and phone numbers. You can also use object lifecycle rules to create automatic expiration policies for your data if you want to make sure that old data files are cleaned up in time.
BigQuery also works with Cloud Data Loss Prevention, also supports table-level expiration but goes even further with partition-level expiration. This method allows you to automatically delete old partitions from a table without touching the rest of the table. Another nice feature is that you can use the BigQuery transformations to track where the data originated from so you know directly from which tables you need to delete certain data points.
Cloud SQL does not support these features out of the box because it relies on the used database to handle the data. Best to check beforehand if the database you are using (for example MySQL) can support data expiration policies.
| Platform | Following data compliance rules is… |
|---|---|
| Cloud Storage | Doable but certainly not easy |
| BigQuery | Easy |
| Cloud SQL | Depends on the database |
Cost aspect
To compare the cost of the data we will assume all data is accessed at least once a month. If data is not used by anyone for more than 1 month, it might not be worth it to port the data over into the data lake.
Cloud storage is priced, at the time of writing, at €45/month per terabyte of data of active storage in the EU multi-region. BigQuery is priced at €19/month per terabyte of data in the EU multi-region. Cloud SQL is a bit harder to estimate because a large portion of the cost goes to the infrastructure that you need to run the actual queries but it is safe to assume that it would cost at least €500 per month to support an active data lake with 1 terabyte of data.
| Platform | Data storage cost is… |
|---|---|
| Cloud Storage | Pretty cheap |
| BigQuery | Cheapest |
| Cloud SQL | Expensive |
Data should be in one place
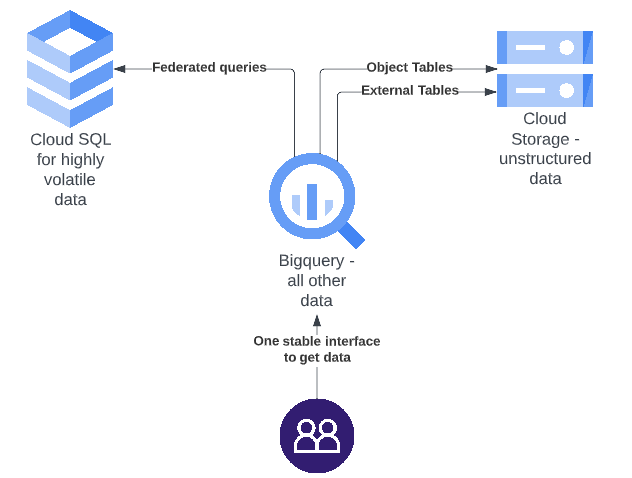
Now I know I suggested multiple platforms to solve all kinds of concerns and according to the definition of Google a data lake is supposed to be one centralised repository, so how do we go from here? Prepare yourself for some database magic in the form of federated queries, BigLake and object tables.
With federated queries, BigQuery is able to query a database in Cloud SQL as if this data lived in BigQuery so we can easily expose the nice interface of BigQuery but still leverage Cloud SQL for the niche data that is highly volatile. Federated queries are a bit slower than queries that only access data embedded in BigQuery but that is normally not a concern for a data lake, the most important thing is that data is available and up to date.
With BigLake you can:
- unify Cloud Storage and BigQuery to query data living in Cloud Storage directly in BigQuery.
- With the recent introduction of object tables you can even run BigQuery queries on the structured metadata of unstructured data blobs that are stored in Cloud Storage.
- Another nice thing about BigLake is that it can also access objects hosted in AWS or Azure.
So if we combine all of the best solutions together, a great data lake platform can look something like the figure below. Where all parts have their specific role but the overall data platform is exposed to the end user via 1 stable interface, the BigQuery interface.
Conclusion
To summarise: every service has its unique challenges, benefits, and way of working so it is not easy to just pick one service and stick with it. Luckily Google also recognized this problem. That is why they introduced BigLake to make sure that, even though you use multiple services to store your data, you will not lose that single interface that is required to manage your data lake.
| Platform | Can handle … data | Data storage cost is | Following data compliance rules is | Using data is | Securing data will be | Finding data will be |
|---|---|---|---|---|---|---|
| Cloud Storage | Unstructured + structured | Pretty cheap | Doable but certainly not easy | Hard | Easy to do at a granular level | Hard to scale |
| BigQuery | structured | Cheapest | Easy | Easy | Easy to do at all levels (granular & super detailed) | Easy |
| Cloud SQL | structured | Expensive | Depends on the database | Easy for dashboarding, hard for sheets | Hard to scale | Easy, if you put additional tools in place. |
| -> BigLake allows you to combine all of those 3 storage options so you can pick the best option based on the data you have |
While a lot of people argue to always use Cloud Storage as a data lake platform because it is the only platform that can store unstructured data I want to argue against this. While Cloud Storage on its own is a great product and definitely the correct platform for some, you have to think about its limitations. The lack of easy data governance, row/column level access control and build-in data processing engine is why companies like Deliverect built their data lake in BigQuery instead of Cloud Storage.
Always picking Cloud Storage because there is a chance that you sometimes have to work with unstructured data is like always driving a truck because sometimes you have to transport a refrigerator. Pick the truck when you have to work with big objects but in all other cases leverage BigQuery for its ease of use, cheap storage and built-in data governance.

Ready to build your data lake on GCP?
Speak with a Google Cloud sales specialist to further discuss the unique challenges you are facing.

