About the customer
The client is a financial services company that manages a large real estate portfolio as part of a REIT (Real Estate Investment Trust). The company is listed on the S&P500 list of companies. With the largest portfolio of apartment housing in the southern United States, the company is located across 300 different communities and provides housing to more than 100.000 families.
The Problem / Challenge
Given the size of our client’s property portfolio, the main pain point was understanding the costs for each property within the portfolio. Accurate cost tracking is important as each property generates monthly water, electricity and gas bills from different suppliers. The costs of the entire property portfolio form the basis for key financial metrics to understand performance within REIT and calculate returns.
Processing billing information and correct payments generate a huge amount of manual work. It is particularly important that they process all invoices timely and correct. A single mistake can have far-reaching consequences, such as the disconnection of a property from the grid or miscalculation of property portfolio performance.
In a competitive and fast-growing environment, the client wanted to automate the processing of utility bills as much as possible. This way, all bills would be processed on time and within budget, while minimising errors.
In previous attempts, the client experimented with Document AI and up training, without satisfactory results. Therefore, the S&P500 client contacted us.
The Solution
Devoteam G Cloud has a lot of experience building solutions based on the Document AI suite. To speed up development processes, we have created our own accelerator that automatically batches calls and optimises resource usage. The resulting architecture is depicted below:
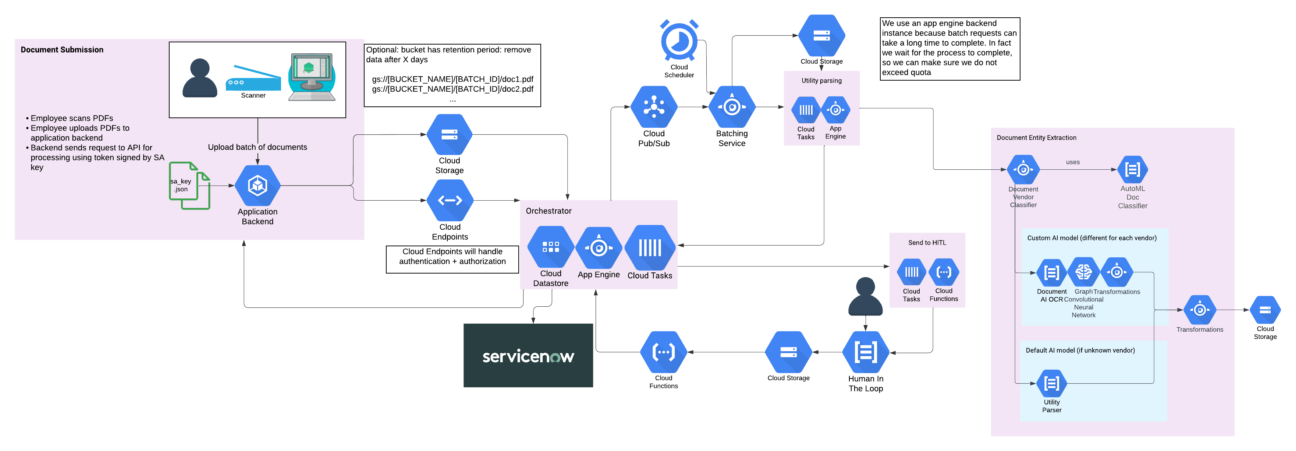
It is battle-tested on a daily basis across several of our customers and is able to process hundreds of millions of documents per month.
For this project, we needed to accommodate a typical Document AI workflow in order to keep manual verification inside of the processes through Human-in-the-Loop (HITL). Therefore, our custom machine learning solution uses documents labelled through HITL as training data and produces predictions that are compatible with the Document AI format. This requirement, in addition to bringing all of Document AI’s features available, makes us able to switch to any other Document AI processor if ever it eventually reaches a better performance than our custom models.
For the custom machine learning model, we opted for Graph Neural Networks, where each node represents a word in a document, and edges are links to the closest words in the document in the four cardinal directions. Each node contains several custom features, notably an embedding of the text as we did in previous works. Thus, this bases our solution on a language model, understanding the text in a document, as well as on a structural model, understanding the relative positions of the texts in a document.
Finally, we use Vertex AI Vizier, Google Cloud’s black-box hyperparameter tuning service, allowing us to find the optimal configuration for our custom model in a matter of hours and reach the best possible performance.
The Methodology
As the S&P500 company deals with a large number of vendors, we had to take a phased approach. In fact, at the beginning of the project, labelling documents took more time to process the bills. To speed up the process, we used active learning: the knowledge built from the model with a very low amount of training data can be leveraged to speed up further labelling, retrain the model and continue until we reach a satisfactory performance. The knowledge built on these vendors then allows us to concentrate efforts on other vendors and bootstrap them much faster.
As always, this machine learning project is mostly based on Google Cloud’s Vertex AI product suite. It allowed us to handle every step of our machine-learning project, from data exploration to model deployment and monitoring. Thanks to its capabilities, we were able to experiment with models and different architecture in a much faster way, allowing us to comply with all the requirements of the customer.
The Result
To evaluate the predictions of our created models, we use the F1 score metric. In a nutshell, the F1 score is made up of two parts: precision and recall. Precision is a measure of how accurate the predictions are. Recall is a measure of how complete the predictions are. To get the F1 score, we take the harmonic mean of the precision and recall scores. This helps evaluate how good the predictions are overall because it takes into account both accuracy and completeness.
At the end of the project, thanks to Vertex AI Vizier which optimised our models’ parameters, we reached a 97.27% F1 score. Compared to the performance of Document AI, this means that the company spends 6x less time labelling thanks to our custom solution.
Please note that an F1-score of 82.6% is already great and sufficient to run in production, but it can be further improved with custom machine-learning models due to the specific challenges of that customer.
| Model | 1-ECE | Precision | Recall | F1 Score |
|---|---|---|---|---|
| DocumentAI | 66.87% | 84.75% | 80.56% | 82.60% |
| Custom model | 96.40% | 97.27% | 97.27% | 97.27% |
Now that the solution is in production, the S&P500 company has onboarded more than 15 different vendors representing up to 20.000 documents per month. While the number of documents handled keeps growing, the team already benefits from the solution in their daily operations, making their workload much lighter, while reducing errors to almost zero.

Are you handling a high volume of documents manually?
Increase Operational Efficiency, Reduce Manual Effort & Accelerate Business Innovation with DocAI.

