About Ocado Retail Ltd
Ocado Retail is a joint venture between Marks & Spencer Group and Ocado Group. They are responsible for ocado.com and Ocado Zoom, the fast-growing, same-day grocery service.
The unique structure enables them to outperform the market, combining award-winning customer service and unrivalled customer data; world-leading technology and logistics from Ocado Group, and unrivalled product development from M&S.
Their ambition is to be the biggest online grocer in the UK.
The outcome of Ocado Retail Ltd’s collaboration with Devoteam G Cloud
After only a couple of weeks of closely working together with Ocado Retail Ltd, we added a new layer on top of the existing data ecosystem to tackle data governance issues that leads to faster and effective search of data, useful insights in the data and more trust in the data. All key features put Ocado Retail into the position to further leverage the existing data ecosystem to analyse their data and support them in their mission to “be the biggest online grocer in the UK”. In the sections below we’ll dive deeper into how exactly we achieved this result together.
The problem
With a big data ecosystem like Ocado Retail Ltd has, there are a lot of pipelines and it can easily be very complex to find your way through the huge data ecosystem. With more data comes more responsibilities. The way users experience data goes beyond dashboards and reports. As the data ecosystem is big, data governance is not easy to manage.
Ocado Retail Ltd wanted to answer the following questions:
- Where can I find data?
- How does the data flow?
- Who has consumed which data?
- What data values can I expect?
- Can I trust the data?
- Who is the owner of the data?
The core of the problem was that there was only a technical way to search data. Analysts struggled to find data and extract insights. To tackle these problems, Devoteam G Cloud implemented the Data Inventory Tool at Ocado Retail Ltd. Devoteam set up a data mesh architecture with Dataplex and created custom Looker Studio dashboards to get insights into who has accessed the data.

Data mesh architecture makes finding data in BigQuery or Cloud Storage easy, even if you don’t know where it’s stored. With the access dashboards, we can see if data is used and by who.
The goal
With the creation of the Data Inventory Tool the key concept was automation. Dataplex harvests all the metadata used in its data mesh structure. Cloud Storage Bucket and BigQuery Dataset metadata automatically update without any manual intervention. The Ocado Retail Ltd data governance lead designed the data mesh structure together with Devoteam G Cloud and used Terraform to implement it. Devoteam G Cloud automated the creation of assets with a generation script.
This metadata provides a single-pane-of-glass view of the Data Inventory Tool with Dataplex. All data governance functionality like data lineage, data steward, business terms, etc. is available in one place.
The methodology and results
Goal 1: automatic metadata harvesting
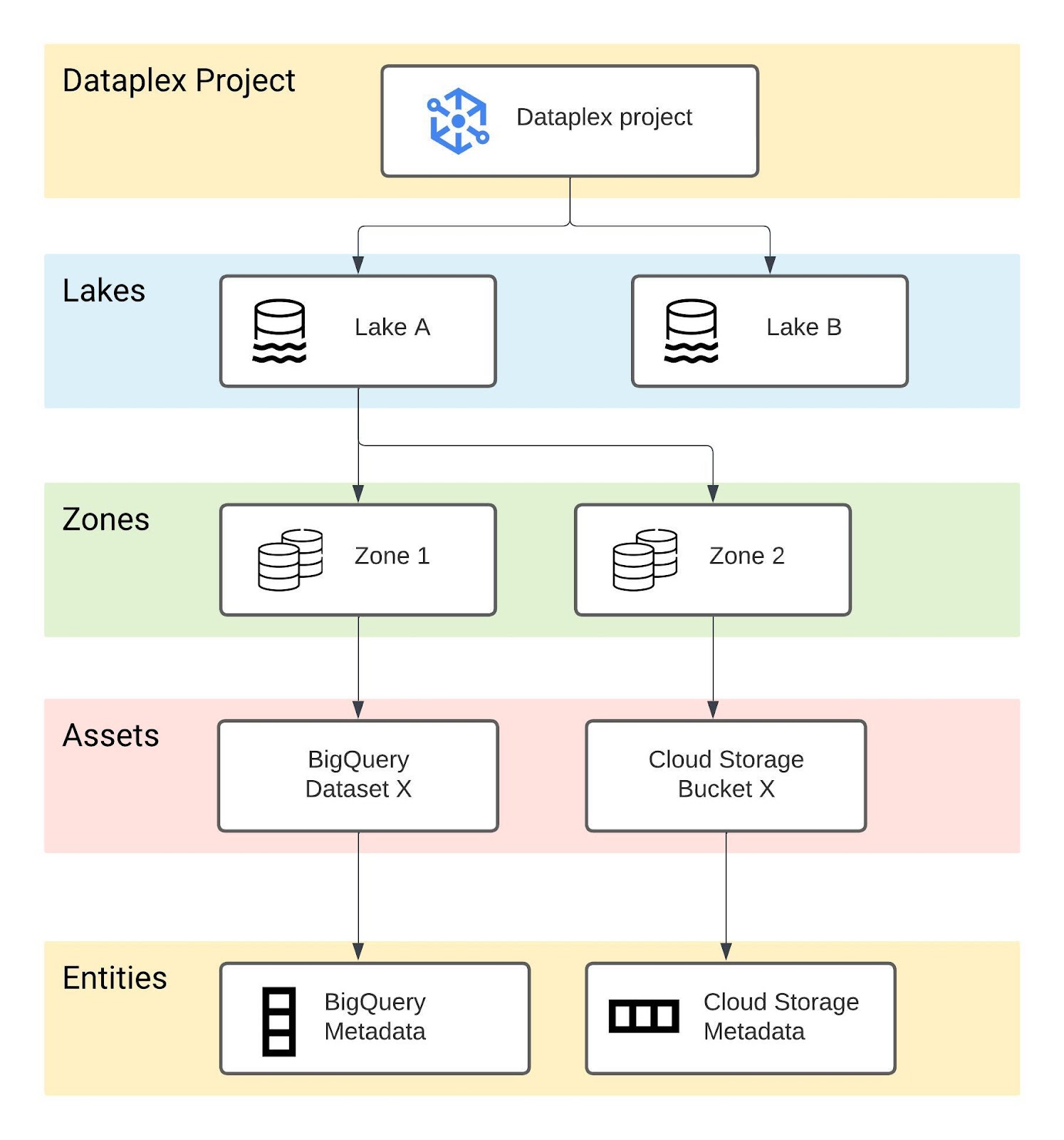
Together with Jim, the data governance lead of Ocado Retail, we created a data mesh architecture implemented with Dataplex lakes, zones, assets and entities. A data mesh is a decentralised data architecture that organises data by a specific business domain, for example, sales, customer service, and marketing.
Let’s discuss the Dataplex architecture:
- Lake: A logical construct representing a data domain or business unit. For example, to organise data based on group usage, you can set up a lake per department (for example, Retail, Sales, Finance).
- Zone: A sub-domain within a lake, useful to categorise data by stage (for example, landing, raw, curated_data_analytics, curated_data_science), usage (for example, data contract), or restrictions (for example, security controls, user access levels). Zones are of two types, raw and curated.
- Raw zone: Data in its raw format and not subject to strict type-checking.
- Curated zone: Data cleaned, formatted, and ready for analytics. The data is columnar, Hive-partitioned, in Parquet, Avro, Orc files, or BigQuery tables. Data undergoes type-checking, for example, to prohibit CSV files because they do not perform as well for SQL access.
- Asset: An asset maps to data stored in either Cloud Storage or BigQuery. You can map data stored in separate Google Cloud projects as assets into a single zone.
- Entity: An entity represents the metadata for structured and semi-structured data (table) and unstructured data (files).
The lakes, zones, and assets were set up with Terraform. Dataplex automates metadata harvesting and configuration with Terraform. See the diagram below.
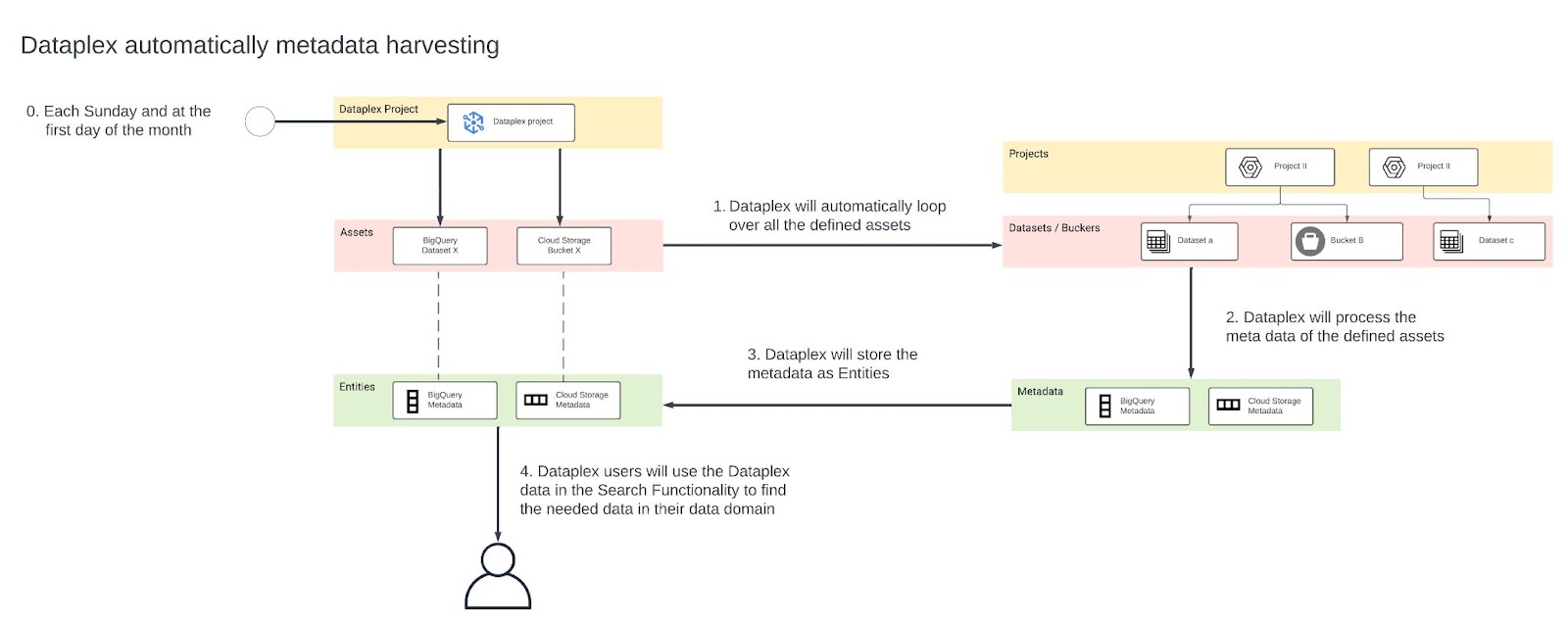
Dataplex users will use the Dataplex harvested data in the search functionality to find the needed data in their domain.
Goal 2: single-pane-of-glass of data governance functionality
With the Dataplex structure (Lakes, Zones, Assets, and Entities) now set up and the metadata loaded, we can use the information in Dataplex for different functionalities. There is a global overview in the following table and we discuss a use case below.
| Dataplex functionality | Explanation |
| Search | Search lakes, zones, assets, and entities like tables. See extra information about the data like Data Lineage, Data Steward, Descriptions |
| Tag templates | Unified tag standards to create, search, and manage metadata for all their data entries in a unified service |
| Policy tags | Define access to your data when you use column-level access control or dynamic data masking. (migrated to BigQuery) |
| Glossaries | Business descriptions |
| Manage | Setup lakes, zones and assets |
| Profile | Identify common statistical characteristics of the columns in your BigQuery tables |
| Data Quality | Add data quality checks |

The potential of data quality looks promising and will save me a lot of time. Currently, I do a lot of work manually.
In the following diagram, we describe the flow of a user who searches data, finds insights and gets trust in the data.
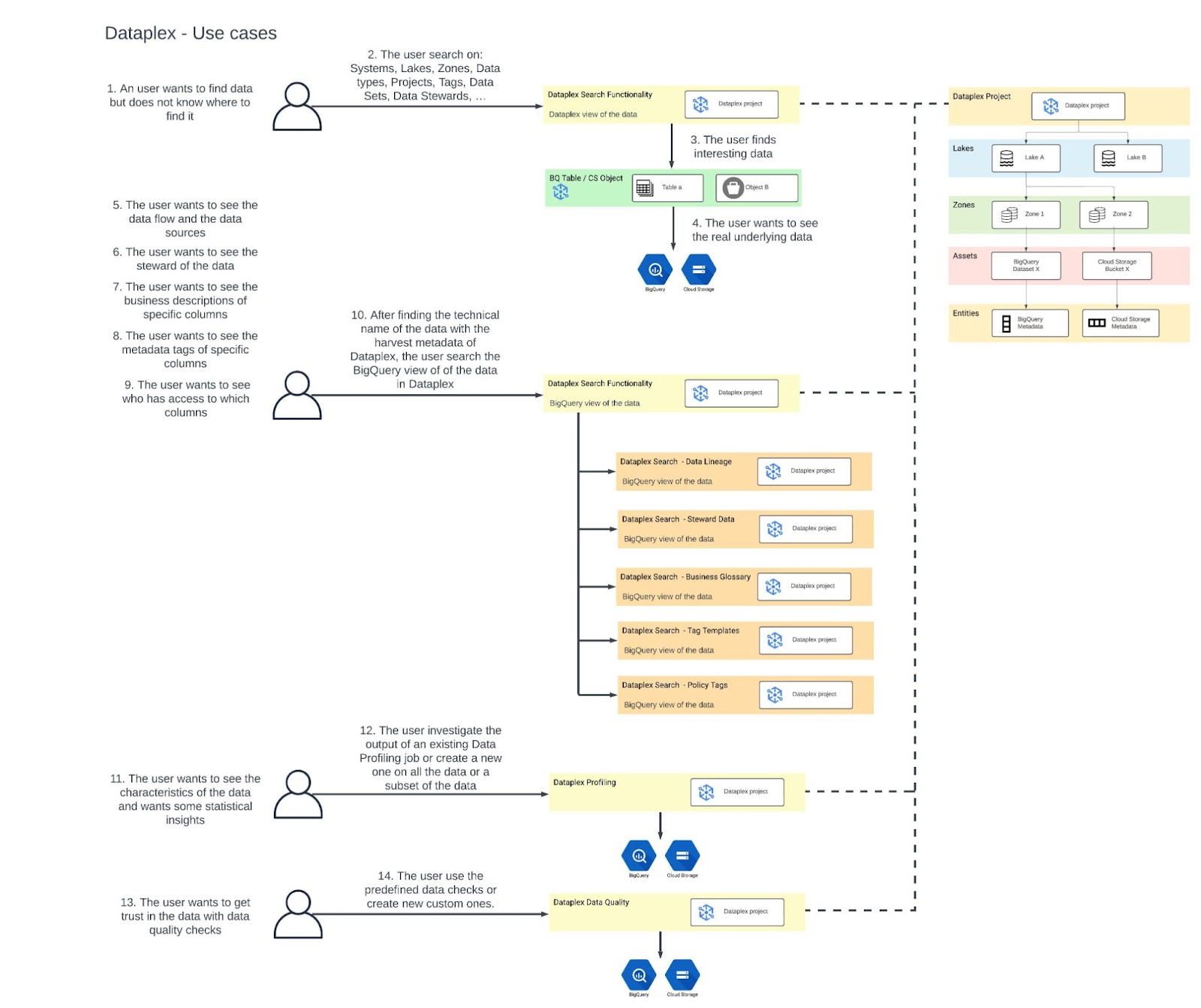

I like the data lineage functionality. We previously lacked this information, but it now clearly shows the data flow and data sources for each table.

Get in touch with us to learn more about how Dataplex can help you improve your data governance.
Benefit from the expertise of a recognized Google Cloud Premier Managed Services Partner. From strong change management to technical excellence and an innovative mindset: Devoteam experts have what it takes to inspire you and make your projects successful.

